diff --git a/docs-mintlify/admin/account-billing/distribution.mdx b/docs-mintlify/admin/account-billing/distribution.mdx
index 887bcdbd8793a..9120951c2b663 100644
--- a/docs-mintlify/admin/account-billing/distribution.mdx
+++ b/docs-mintlify/admin/account-billing/distribution.mdx
@@ -124,4 +124,4 @@ open http://localhost:3000
[ref-infrastructure]: /admin/deployment/infrastructure
[ref-workspace]: /admin/workspace
[ref-deployment]: /admin/deployment
-[ref-update-channels]: /admin/deployment/deployments#update-channels
\ No newline at end of file
+[ref-update-channels]: /admin/deployment/index#update-channels
\ No newline at end of file
diff --git a/docs-mintlify/admin/connect-to-data/data-sources/ksqldb.mdx b/docs-mintlify/admin/connect-to-data/data-sources/ksqldb.mdx
index 72c3dd60c56b4..c78f6d2210f83 100644
--- a/docs-mintlify/admin/connect-to-data/data-sources/ksqldb.mdx
+++ b/docs-mintlify/admin/connect-to-data/data-sources/ksqldb.mdx
@@ -349,6 +349,19 @@ cubes:
- CUBE.user_id
- CUBE.status
stream_offset: latest
+ output_column_types:
+ - member: CUBE.order_id
+ type: text
+ - member: CUBE.user_id
+ type: text
+ - member: CUBE.status
+ type: text
+ - member: CUBE.count
+ type: int
+ - member: CUBE.total_amount
+ type: decimal
+ - member: CUBE.failed_count
+ type: int
```
```javascript title="JavaScript"
@@ -514,6 +527,14 @@ cube("order_events_stream", {
},
},
stream_offset: `latest`,
+ output_column_types: [
+ { member: CUBE.order_id, type: `text` },
+ { member: CUBE.user_id, type: `text` },
+ { member: CUBE.status, type: `text` },
+ { member: CUBE.count, type: `int` },
+ { member: CUBE.total_amount, type: `decimal` },
+ { member: CUBE.failed_count, type: `int` },
+ ],
},
},
});
@@ -533,6 +554,9 @@ Key properties for the streaming pre-aggregation:
from the last processed offset regardless of this setting.
- `unique_key_columns` — columns that uniquely identify a record, used
for deduplication (see [below](#unique-key-columns-and-deduplication)).
+- `output_column_types` — declares the output column types for the Cube
+ Store table, required for Kafka streams mode (see
+ [below](#output-column-types)).
#### Primary key and ungrouped queries
@@ -557,6 +581,35 @@ or table. Cube discovers its schema automatically. With Kafka streams
mode enabled, the streaming pre-aggregation reads the backing Kafka topic
directly — no objects are created in ksqlDB.
+#### Topic name matching {#topic-name-matching}
+
+In Kafka streams mode, Cube Store parses the `select_statement`
+(generated from the cube's `sql` property) and matches the `FROM` table
+name against the actual Kafka topic name. On managed platforms like
+Confluent Cloud, the Kafka topic name often differs from the ksqlDB
+stream or table name — for example, a ksqlDB stream called
+`ORDER_EVENTS_STREAM` might be backed by a Kafka topic named
+`pksqlc-abc123ORDER_EVENTS_STREAM`.
+
+The cube's `sql` property must reference the **ksqlDB stream or table
+name** (not the Kafka topic), because Cube uses ksqlDB `DESCRIBE` to
+discover the schema and resolve the backing topic. However, Cube does
+not currently rewrite the `FROM` clause in the generated
+`select_statement` to use the resolved Kafka topic name. If the ksqlDB
+object name differs from the Kafka topic name, Cube Store will fail
+with:
+
+> Topic table ORDER_EVENTS_STREAM is not found
+
+
+
+This is a known limitation of Kafka streams mode. It does not occur
+when the ksqlDB object name and the Kafka topic name are the same,
+which is the default behavior when ksqlDB creates a stream or table
+with the default topic naming strategy.
+
+
+
### Unique key columns and deduplication
When `unique_key_columns` is set, Cube Store appends an internal
@@ -579,6 +632,135 @@ falls back to the Kafka message key: for a single unique key column, the
raw key value is used; for composite keys, the key is expected to be a
JSON object with matching field names.
+### Output column types
+
+In Kafka streams mode, Cube Store creates its internal pre-aggregation
+table based on column type information. By default, column types are
+inferred from the source ksqlDB stream using `DESCRIBE`. However, the
+pre-aggregation's `select_statement` (generated from the rollup
+definition) renames and transforms columns — for example, a source
+column `CREATED_AT` becomes `order_events_stream__created_at_second` in
+the output.
+
+When this renaming happens, the raw source column types no longer match
+the output column names, causing errors like:
+
+> Key column `order_events_stream__id` not found among column definitions
+
+To fix this, define `output_column_types` on the streaming
+pre-aggregation. This tells Cube the exact output column types to use
+for the Cube Store table, and separately passes the source schema so
+Cube Store can deserialize the raw Kafka messages correctly.
+
+
+
+```yaml title="YAML"
+pre_aggregations:
+ - name: stream
+ type: rollup
+ read_only: true
+ measures:
+ - CUBE.count
+ - CUBE.total_amount
+ - CUBE.failed_count
+ dimensions:
+ - CUBE.order_id
+ - CUBE.user_id
+ - CUBE.status
+ unique_key_columns:
+ - order_id
+ time_dimension: CUBE.created_at
+ granularity: second
+ partition_granularity: day
+ build_range_start:
+ sql: "SELECT date_trunc('day', DATE_SUB(NOW(), INTERVAL '5 hour'))"
+ build_range_end:
+ sql: "SELECT DATE_ADD(NOW(), INTERVAL '15 minute')"
+ refresh_key:
+ every: 1 minute
+ update_window: 1 hour
+ incremental: true
+ stream_offset: latest
+ output_column_types:
+ - member: CUBE.order_id
+ type: text
+ - member: CUBE.user_id
+ type: text
+ - member: CUBE.status
+ type: text
+ - member: CUBE.count
+ type: int
+ - member: CUBE.total_amount
+ type: decimal
+ - member: CUBE.failed_count
+ type: int
+```
+
+```javascript title="JavaScript"
+pre_aggregations: {
+ stream: {
+ type: `rollup`,
+ read_only: true,
+ measures: [CUBE.count, CUBE.total_amount, CUBE.failed_count],
+ dimensions: [CUBE.order_id, CUBE.user_id, CUBE.status],
+ unique_key_columns: [`order_id`],
+ time_dimension: CUBE.created_at,
+ granularity: `second`,
+ partition_granularity: `day`,
+ build_range_start: {
+ sql: `SELECT date_trunc('day', DATE_SUB(NOW(), INTERVAL '5 hour'))`,
+ },
+ build_range_end: {
+ sql: `SELECT DATE_ADD(NOW(), INTERVAL '15 minute')`,
+ },
+ refresh_key: {
+ every: `1 minute`,
+ update_window: `1 hour`,
+ incremental: true,
+ },
+ stream_offset: `latest`,
+ output_column_types: [
+ { member: CUBE.order_id, type: `text` },
+ { member: CUBE.user_id, type: `text` },
+ { member: CUBE.status, type: `text` },
+ { member: CUBE.count, type: `int` },
+ { member: CUBE.total_amount, type: `decimal` },
+ { member: CUBE.failed_count, type: `int` },
+ ],
+ },
+},
+```
+
+
+
+Each entry in `output_column_types` has two properties:
+
+- `member` — a reference to a dimension or measure included in the
+ pre-aggregation.
+- `type` — the Cube Store column type. Common values: `text`, `int`,
+ `bigint`, `decimal`, `float`, `boolean`, `timestamp`.
+
+The time dimension used in `time_dimension` does not need an entry in
+`output_column_types` — its type is always `timestamp` and is set
+automatically.
+
+When `output_column_types` is defined, Cube uses the aliased column
+names (matching the `select_statement`) for the Cube Store table
+definition and passes the raw source schema separately via
+`source_table`, so Cube Store knows how to deserialize incoming Kafka
+messages. Without it, column names come from the raw ksqlDB `DESCRIBE`
+output and will not match the aliased names in the `select_statement`
+or `unique_key_columns`.
+
+
+
+`output_column_types` is required for Kafka streams mode when the
+pre-aggregation uses `unique_key_columns`. Without it, the unique key
+column names will not match the table column definitions, causing the
+pre-aggregation build to fail.
+
+
+
### Stream format
Cube Store expects Kafka messages to have a **JSON object** as their
diff --git a/docs-mintlify/admin/deployment/auto-suspension.mdx b/docs-mintlify/admin/deployment/auto-suspension.mdx
index 972865fe64012..20a8dd79de4f4 100644
--- a/docs-mintlify/admin/deployment/auto-suspension.mdx
+++ b/docs-mintlify/admin/deployment/auto-suspension.mdx
@@ -124,4 +124,4 @@ response times to be significantly longer than usual.
[self-effects]: #effects-on-experience
[ref-refresh-worker]: /cube-core/architecture#refresh-worker
[ref-sls]: /docs/integrations/semantic-layer-sync#on-schedule
-[ref-cube-version]: /admin/deployment/deployments#cube-version
\ No newline at end of file
+[ref-cube-version]: /admin/deployment/index#cube-version
\ No newline at end of file
diff --git a/docs-mintlify/admin/deployment/environments.mdx b/docs-mintlify/admin/deployment/environments.mdx
index a95d411660a96..1aa6f0150537e 100644
--- a/docs-mintlify/admin/deployment/environments.mdx
+++ b/docs-mintlify/admin/deployment/environments.mdx
@@ -9,12 +9,6 @@ Every Cube Cloud deployment provides a number of environments:
- Multiple [staging environments](#staging-environments).
- Per-user [development environments](#development-environments).
-
-
-Available on [all plans](https://cube.dev/pricing).
-
-
-
## Production environment
This is the main environment. It runs the data model from the _main branch_.
@@ -120,5 +114,5 @@ credentials**][ref-credentials].
[ref-suspend]: /docs/deployment/cloud/auto-suspension
[ref-overview]: /docs/workspace/integrations#review-integrations
[ref-credentials]: /docs/workspace/integrations#view-api-credentials
-[ref-version]: /docs/deployment/cloud/deployments#cube-version
-[ref-version-channel]: /docs/deployment/cloud/deployments#update-channels
\ No newline at end of file
+[ref-version]: /admin/deployment/index#cube-version
+[ref-version-channel]: /admin/deployment/index#update-channels
\ No newline at end of file
diff --git a/docs-mintlify/admin/deployment/index.mdx b/docs-mintlify/admin/deployment/index.mdx
index 512058600c136..0a9a7f73f0df1 100644
--- a/docs-mintlify/admin/deployment/index.mdx
+++ b/docs-mintlify/admin/deployment/index.mdx
@@ -147,7 +147,7 @@ You can view or change the update channel by navigating to **Settings →
General → Cube version**:
-
+
You can select a specific version in the drop-down. Only versions that have been used by
diff --git a/docs-mintlify/admin/deployment/infrastructure.mdx b/docs-mintlify/admin/deployment/infrastructure.mdx
index ebc9a2ab29e65..4bee7d6f2f195 100644
--- a/docs-mintlify/admin/deployment/infrastructure.mdx
+++ b/docs-mintlify/admin/deployment/infrastructure.mdx
@@ -26,12 +26,6 @@ scaling, and monitoring your Cube Deployments, as well as managing Cube Store
and persisting pre-aggregated data. This option requires the least effort to
set up.
-
-
-Available on [all plans](https://cube.dev/pricing).
-
-
-
Please note that some Enterprise features, such as VPC peering or PrivateLink are
not available on the multi-tenant infrastructure. There's also a possibility of
resource contention ("noisy neighbor") problem.
diff --git a/docs-mintlify/admin/monitoring/pre-aggregations.mdx b/docs-mintlify/admin/monitoring/pre-aggregations.mdx
index 49958e0f80c76..87692c309018b 100644
--- a/docs-mintlify/admin/monitoring/pre-aggregations.mdx
+++ b/docs-mintlify/admin/monitoring/pre-aggregations.mdx
@@ -9,12 +9,6 @@ can see which pre-aggregations are accelerating queries, if they are [being
refreshed][ref-caching-using-preaggs-refresh], along with the last 24 hours of
build history.
-
-
-Available on [all plans](https://cube.dev/pricing).
-
-
-
diff --git a/docs-mintlify/admin/monitoring/query-history.mdx b/docs-mintlify/admin/monitoring/query-history.mdx
index 438e2da63e98d..511a93f2ba6f9 100644
--- a/docs-mintlify/admin/monitoring/query-history.mdx
+++ b/docs-mintlify/admin/monitoring/query-history.mdx
@@ -10,8 +10,8 @@ failed.
-Available on [all plans](https://cube.dev/pricing).
-You can also choose a [Query History tier](/admin/account-billing/pricing#query-history-tiers).
+You can choose a [Query History tier](/admin/account-billing/pricing#query-history-tiers)
+to fit your retention and throughput needs.
diff --git a/docs-mintlify/docs.json b/docs-mintlify/docs.json
index 2fac5fa690c74..724945f33bb93 100644
--- a/docs-mintlify/docs.json
+++ b/docs-mintlify/docs.json
@@ -175,7 +175,8 @@
"pages": [
"docs/data-modeling/visual-modeler",
"docs/data-modeling/data-model-ide",
- "docs/data-modeling/dev-mode"
+ "docs/data-modeling/dev-mode",
+ "docs/data-modeling/access-policies-viewer"
]
}
]
diff --git a/docs-mintlify/docs/data-modeling/access-control/context.mdx b/docs-mintlify/docs/data-modeling/access-control/context.mdx
index d9f6626f4ff68..b0cca7e0fe97d 100644
--- a/docs-mintlify/docs/data-modeling/access-control/context.mdx
+++ b/docs-mintlify/docs/data-modeling/access-control/context.mdx
@@ -300,12 +300,6 @@ enrich the security context with additional attributes.
When using Cube Cloud, you can enrich the security context with information about
an authenticated user, obtained during their authentication.
-
-
-Available on [all plans](https://cube.dev/pricing).
-
-
-
You can enable the authentication integration by navigating to the **Settings → Configuration**
of your Cube Cloud deployment and using the **Enable Cloud Auth Integration** toggle.
diff --git a/docs-mintlify/docs/data-modeling/access-policies-viewer.mdx b/docs-mintlify/docs/data-modeling/access-policies-viewer.mdx
new file mode 100644
index 0000000000000..b4875fe8ee07d
--- /dev/null
+++ b/docs-mintlify/docs/data-modeling/access-policies-viewer.mdx
@@ -0,0 +1,85 @@
+---
+title: Access Policies viewer
+description: Audit row-level, member-level, and member-masking access policies that govern your data model from the Cube Cloud UI, grouped by user group.
+---
+
+The Access Policies viewer surfaces, in one place, every [access policy][ref-access-policies]
+defined in your [data model][ref-data-modeling] — row-level filters, member-level
+restrictions, and member masking — broken down by the user [groups][ref-user-groups]
+they apply to.
+
+Use it to audit who can see which cubes and views, and how each policy is composed,
+without grepping through `cube` files or running test queries.
+
+
+
+The viewer is read-only. Access policies themselves are authored in the
+[data model][ref-access-policies] using `access_policy` blocks; this page
+visualizes the resolved rules so you can review and debug them.
+
+
+
+## Opening the viewer
+
+In Cube Cloud, navigate to the **Model** module and click **Access Policies** in
+the sub-sidebar. The viewer reflects whichever branch and build you are currently
+viewing, so policies you are editing in [development mode][ref-dev-mode] appear
+alongside what is live in production.
+
+You need the `PlaygroundRead` permission to open the viewer.
+
+## List view
+
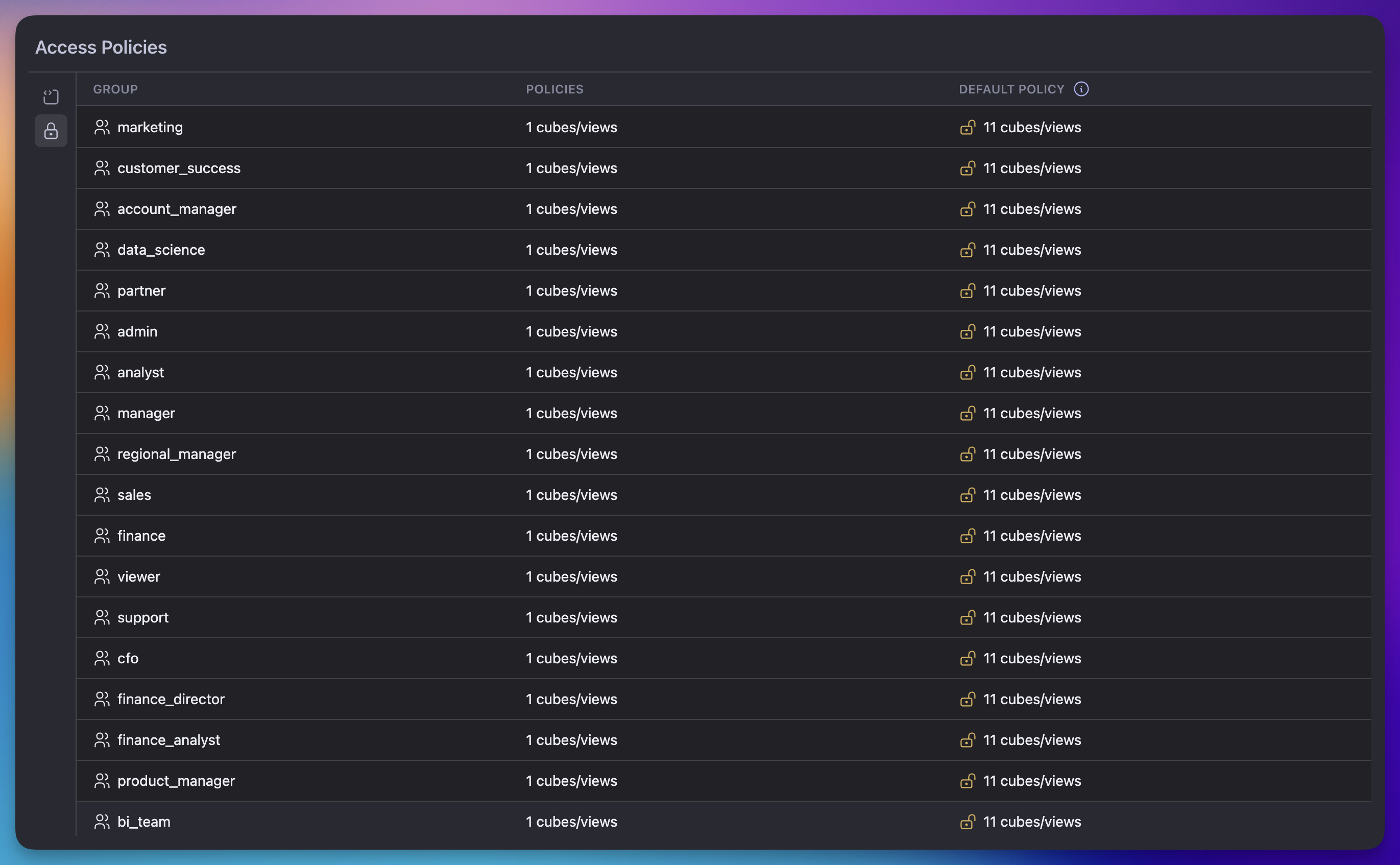
+The list view shows one row per group declared anywhere in the data model:
+
+
+
+
+
+
+| Column | What it shows |
+| --- | --- |
+| **Group** | Name of the group. The wildcard entry `*` is rendered as **All Groups** — this is the catch-all default policy applied when no other policy matches. |
+| **Policies** | Number of cubes and views with an explicit policy for this group. Hover the cell to see the full list of cube and view names. |
+| **Default Policy** | Number of cubes and views this group can access without an explicit policy — the union of cubes covered by the wildcard `*` policy and any cubes that have no policy at all. |
+
+Cubes and views with no `access_policy` block defined are considered fully open;
+they appear under **Default Policy** for every group.
+
+Click a row to drill into the per-cube breakdown for that group.
+
+## Per-policy detail view
+
+The detail view shows one row per cube or view that the selected group can
+access, with the resolved policy expanded across four columns:
+
+| Column | What it shows |
+| --- | --- |
+| **Cube / View** | Name of the cube or view, with an icon distinguishing the two. |
+| **Condition** | The number of [`condition`][ref-policy-condition] expressions on the policy, or `—` if the policy applies unconditionally. Conditions are arbitrary expressions defined in the model. |
+| **Member-level Access** | One of three states: **Allow All** (no member-level restrictions), **Deny All** (member access is fully denied), or **Allow:** followed by the resolved set of allowed dimensions, segments, and measures. |
+| **Member Masking** | `—` if no [member masking][ref-mls-masking] applies, otherwise the list of masked dimensions. |
+| **Row-level Access** | Either **Allow All**, or **Filters on:** followed by the dimensions referenced by the row-level filter. |
+
+Member names are shortened to the last path segment for readability — for
+example, `orders.user.email` is shown as `email`.
+
+## What the viewer does not do
+
+The viewer is intentionally scoped to inspecting policies that are already
+defined in the model. It does not:
+
+- Create, edit, or delete access policies. Edit `access_policy` blocks in your
+ data model and commit through your normal Git workflow.
+- Show which individual users belong to a given group. See
+ [User groups][ref-user-groups] for membership management.
+- Run preview queries against a policy. To verify behavior end-to-end, switch
+ the security context and issue queries against your development API.
+
+
+[ref-data-modeling]: /docs/data-modeling/overview
+[ref-access-policies]: /docs/data-modeling/data-access-policies
+[ref-policy-condition]: /reference/data-modeling/data-access-policies#conditions
+[ref-mls-masking]: /docs/data-modeling/data-access-policies#data-masking
+[ref-dev-mode]: /docs/data-modeling/dev-mode
+[ref-user-groups]: /admin/users-and-permissions/user-groups
\ No newline at end of file
diff --git a/docs-mintlify/docs/data-modeling/data-model-ide.mdx b/docs-mintlify/docs/data-modeling/data-model-ide.mdx
index 8d5daa3076c15..f22e5800d9654 100644
--- a/docs-mintlify/docs/data-modeling/data-model-ide.mdx
+++ b/docs-mintlify/docs/data-modeling/data-model-ide.mdx
@@ -9,12 +9,6 @@ Data model editor provides the code-first experience for building and enhancing
Unlike the [Visual Modeler][ref-visual-model] editor, it provides the freedom to use all
available data modeling features at the expense of a code-centric experience.
-
-
-Available on [all plans](https://cube.dev/pricing).
-
-
-
Cube Cloud can create branch-based development API instances to quickly test
changes in the data model in your frontend applications before pushing them into
production.
diff --git a/docs-mintlify/docs/data-modeling/dev-mode.mdx b/docs-mintlify/docs/data-modeling/dev-mode.mdx
index 62f12054dfb9a..5d5349a657046 100644
--- a/docs-mintlify/docs/data-modeling/dev-mode.mdx
+++ b/docs-mintlify/docs/data-modeling/dev-mode.mdx
@@ -6,12 +6,6 @@ description: Outlines development mode in Cube Cloud—branch-scoped APIs, save
Development mode allows to test and debug the data model in an isolated
[development environment][ref-environments-dev] before releasing any changes to production.
-
-
-Available on [all plans](https://cube.dev/pricing).
-
-
-
When you enter the development mode, you'll have access to your personal API endpoints
that will track the branch you're on and will be updated automatically when you make
changes to the data model.
diff --git a/docs-mintlify/docs/data-modeling/sql-runner.mdx b/docs-mintlify/docs/data-modeling/sql-runner.mdx
index f6239f2a56360..4e7e0bbe97a2d 100644
--- a/docs-mintlify/docs/data-modeling/sql-runner.mdx
+++ b/docs-mintlify/docs/data-modeling/sql-runner.mdx
@@ -8,12 +8,6 @@ on your data source or Cube Store. It can be used to inform the development of
the data model, for ad-hoc querying as well as debugging SQL queries generated
by Cube to execute against the data source.
-
-
-Available on [all plans](https://cube.dev/pricing).
-
-
-
 +
+
+
+| Column | What it shows |
+| --- | --- |
+| **Group** | Name of the group. The wildcard entry `*` is rendered as **All Groups** — this is the catch-all default policy applied when no other policy matches. |
+| **Policies** | Number of cubes and views with an explicit policy for this group. Hover the cell to see the full list of cube and view names. |
+| **Default Policy** | Number of cubes and views this group can access without an explicit policy — the union of cubes covered by the wildcard `*` policy and any cubes that have no policy at all. |
+
+Cubes and views with no `access_policy` block defined are considered fully open;
+they appear under **Default Policy** for every group.
+
+Click a row to drill into the per-cube breakdown for that group.
+
+## Per-policy detail view
+
+The detail view shows one row per cube or view that the selected group can
+access, with the resolved policy expanded across four columns:
+
+| Column | What it shows |
+| --- | --- |
+| **Cube / View** | Name of the cube or view, with an icon distinguishing the two. |
+| **Condition** | The number of [`condition`][ref-policy-condition] expressions on the policy, or `—` if the policy applies unconditionally. Conditions are arbitrary expressions defined in the model. |
+| **Member-level Access** | One of three states: **Allow All** (no member-level restrictions), **Deny All** (member access is fully denied), or **Allow:** followed by the resolved set of allowed dimensions, segments, and measures. |
+| **Member Masking** | `—` if no [member masking][ref-mls-masking] applies, otherwise the list of masked dimensions. |
+| **Row-level Access** | Either **Allow All**, or **Filters on:** followed by the dimensions referenced by the row-level filter. |
+
+Member names are shortened to the last path segment for readability — for
+example, `orders.user.email` is shown as `email`.
+
+## What the viewer does not do
+
+The viewer is intentionally scoped to inspecting policies that are already
+defined in the model. It does not:
+
+- Create, edit, or delete access policies. Edit `access_policy` blocks in your
+ data model and commit through your normal Git workflow.
+- Show which individual users belong to a given group. See
+ [User groups][ref-user-groups] for membership management.
+- Run preview queries against a policy. To verify behavior end-to-end, switch
+ the security context and issue queries against your development API.
+
+
+[ref-data-modeling]: /docs/data-modeling/overview
+[ref-access-policies]: /docs/data-modeling/data-access-policies
+[ref-policy-condition]: /reference/data-modeling/data-access-policies#conditions
+[ref-mls-masking]: /docs/data-modeling/data-access-policies#data-masking
+[ref-dev-mode]: /docs/data-modeling/dev-mode
+[ref-user-groups]: /admin/users-and-permissions/user-groups
\ No newline at end of file
diff --git a/docs-mintlify/docs/data-modeling/data-model-ide.mdx b/docs-mintlify/docs/data-modeling/data-model-ide.mdx
index 8d5daa3076c15..f22e5800d9654 100644
--- a/docs-mintlify/docs/data-modeling/data-model-ide.mdx
+++ b/docs-mintlify/docs/data-modeling/data-model-ide.mdx
@@ -9,12 +9,6 @@ Data model editor provides the code-first experience for building and enhancing
Unlike the [Visual Modeler][ref-visual-model] editor, it provides the freedom to use all
available data modeling features at the expense of a code-centric experience.
-
+
+
+
+| Column | What it shows |
+| --- | --- |
+| **Group** | Name of the group. The wildcard entry `*` is rendered as **All Groups** — this is the catch-all default policy applied when no other policy matches. |
+| **Policies** | Number of cubes and views with an explicit policy for this group. Hover the cell to see the full list of cube and view names. |
+| **Default Policy** | Number of cubes and views this group can access without an explicit policy — the union of cubes covered by the wildcard `*` policy and any cubes that have no policy at all. |
+
+Cubes and views with no `access_policy` block defined are considered fully open;
+they appear under **Default Policy** for every group.
+
+Click a row to drill into the per-cube breakdown for that group.
+
+## Per-policy detail view
+
+The detail view shows one row per cube or view that the selected group can
+access, with the resolved policy expanded across four columns:
+
+| Column | What it shows |
+| --- | --- |
+| **Cube / View** | Name of the cube or view, with an icon distinguishing the two. |
+| **Condition** | The number of [`condition`][ref-policy-condition] expressions on the policy, or `—` if the policy applies unconditionally. Conditions are arbitrary expressions defined in the model. |
+| **Member-level Access** | One of three states: **Allow All** (no member-level restrictions), **Deny All** (member access is fully denied), or **Allow:** followed by the resolved set of allowed dimensions, segments, and measures. |
+| **Member Masking** | `—` if no [member masking][ref-mls-masking] applies, otherwise the list of masked dimensions. |
+| **Row-level Access** | Either **Allow All**, or **Filters on:** followed by the dimensions referenced by the row-level filter. |
+
+Member names are shortened to the last path segment for readability — for
+example, `orders.user.email` is shown as `email`.
+
+## What the viewer does not do
+
+The viewer is intentionally scoped to inspecting policies that are already
+defined in the model. It does not:
+
+- Create, edit, or delete access policies. Edit `access_policy` blocks in your
+ data model and commit through your normal Git workflow.
+- Show which individual users belong to a given group. See
+ [User groups][ref-user-groups] for membership management.
+- Run preview queries against a policy. To verify behavior end-to-end, switch
+ the security context and issue queries against your development API.
+
+
+[ref-data-modeling]: /docs/data-modeling/overview
+[ref-access-policies]: /docs/data-modeling/data-access-policies
+[ref-policy-condition]: /reference/data-modeling/data-access-policies#conditions
+[ref-mls-masking]: /docs/data-modeling/data-access-policies#data-masking
+[ref-dev-mode]: /docs/data-modeling/dev-mode
+[ref-user-groups]: /admin/users-and-permissions/user-groups
\ No newline at end of file
diff --git a/docs-mintlify/docs/data-modeling/data-model-ide.mdx b/docs-mintlify/docs/data-modeling/data-model-ide.mdx
index 8d5daa3076c15..f22e5800d9654 100644
--- a/docs-mintlify/docs/data-modeling/data-model-ide.mdx
+++ b/docs-mintlify/docs/data-modeling/data-model-ide.mdx
@@ -9,12 +9,6 @@ Data model editor provides the code-first experience for building and enhancing
Unlike the [Visual Modeler][ref-visual-model] editor, it provides the freedom to use all
available data modeling features at the expense of a code-centric experience.
-