|
| 1 | +# 01-LangChain的Hello World项目 |
| 2 | + |
| 3 | + |
| 4 | + |
| 5 | +```python |
| 6 | +pip install --upgrade langchain==0.0.279 -i https://pypi.org/simple |
| 7 | +``` |
| 8 | + |
| 9 | +## 1 创建一个LLM |
| 10 | + |
| 11 | +- 自有算力平台+开源大模型(需要有庞大的GPU资源)企业自己训练数据 |
| 12 | +- 第三方大模型API(openai/百度文心/阿里通义千问...)数据无所谓 |
| 13 | + |
| 14 | +让LLM给孩子起具有中国特色的名字。 |
| 15 | + |
| 16 | +在LangChain中最基本的功能就是根据文本提示来生成新的文本 |
| 17 | + |
| 18 | +使用方法:predict |
| 19 | + |
| 20 | +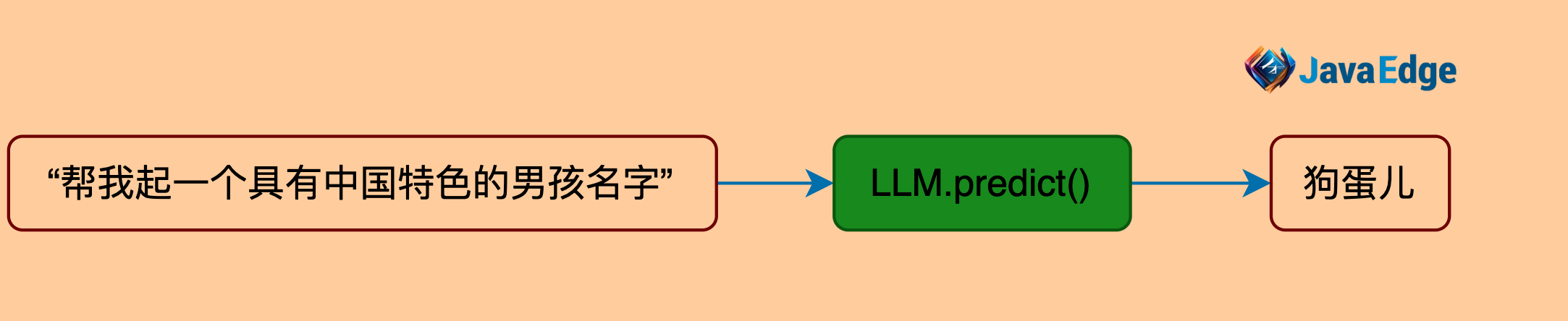 |
| 21 | + |
| 22 | +生成结果根据你调用的模型不同而会产生非常不同的结果差距,并且你的模型的tempurature参数也会直接影响最终结果(即LLM的灵敏度)。 |
| 23 | + |
| 24 | +## 2 自定义提示词模版 |
| 25 | + |
| 26 | +- 将提问的上下文模版化 |
| 27 | +- 支持参数传入 |
| 28 | + |
| 29 | +让LLM给孩子起**具有美国**特色的名字。 |
| 30 | + |
| 31 | +将提示词模版化后会产生很多灵活多变的应用,尤其当它支持参数定义时。 |
| 32 | + |
| 33 | +### 使用方法 |
| 34 | + |
| 35 | +langchain.prompts |
| 36 | + |
| 37 | +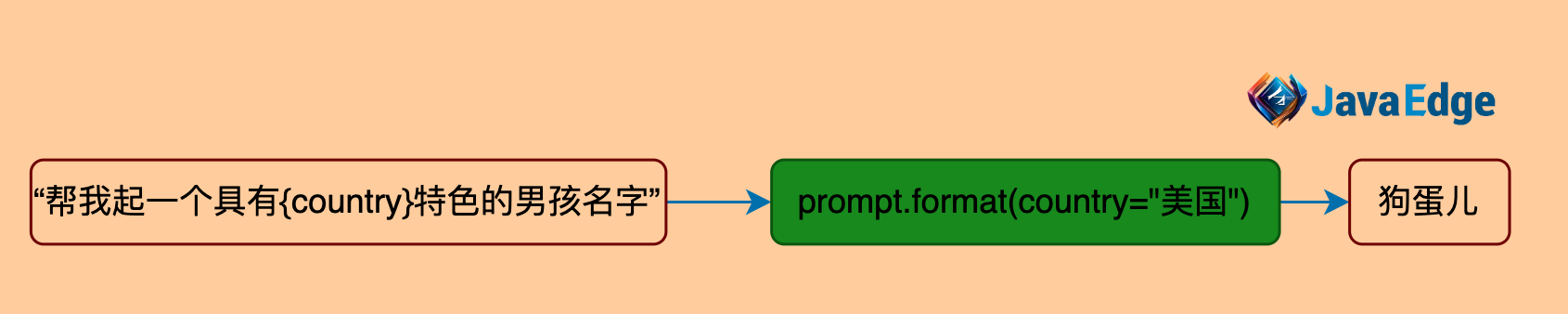 |
| 38 | + |
| 39 | +## 3 输出解释器 |
| 40 | + |
| 41 | +- 将LLM输出的结果各种格式化 |
| 42 | +- 支持类似json等结构化数据输出 |
| 43 | + |
| 44 | +让LLM给孩子起4个有中国特色的名字,并以数组格式输出而不是文本。 |
| 45 | + |
| 46 | +与chatGPT只能输出文本不同,langchain允许用户自定义输出解释器,将生成文本转化为序列数据使用方法: |
| 47 | + |
| 48 | +langchain.schema |
| 49 | + |
| 50 | + |
| 51 | + |
| 52 | +### 第一个实例 |
| 53 | + |
| 54 | +让LLM以人机对话的形式输出4个名字 |
| 55 | + |
| 56 | +名字和性别可以根据用户输出来相应输出 |
| 57 | + |
| 58 | +输出格式定义为数组 |
| 59 | + |
| 60 | +## 4 开始运行 |
| 61 | + |
| 62 | + |
| 63 | + |
| 64 | +```bash |
| 65 | +pip install openai==v0.28.1 -i https://pypi.org/simple |
| 66 | +``` |
| 67 | + |
| 68 | +### 引入openai key |
| 69 | + |
| 70 | +```python |
| 71 | +import os |
| 72 | +os.environ["OPENAI_KEY"] = "sk-ss" |
| 73 | +# 为了科学上网,所以需要添加 |
| 74 | +os.environ["OPENAI_API_BASE"] = "https://ai-yyds.com/v1" |
| 75 | +``` |
| 76 | + |
| 77 | +从环境变量中读取: |
| 78 | + |
| 79 | +```python |
| 80 | +import os |
| 81 | +openai_api_key = os.getenv("OPENAI_KEY") |
| 82 | +openai_api_base = os.getenv("OPENAI_API_BASE") |
| 83 | +print("OPENAI_API_KEY:", openai_api_key) |
| 84 | +print("OPENAI_PROXY:", openai_api_base) |
| 85 | +``` |
| 86 | + |
| 87 | +### 运行前查看下安装情况 |
| 88 | + |
| 89 | +``` |
| 90 | +! pip show langchain |
| 91 | +! pip show openai |
| 92 | +``` |
| 93 | + |
| 94 | + |
| 95 | + |
| 96 | +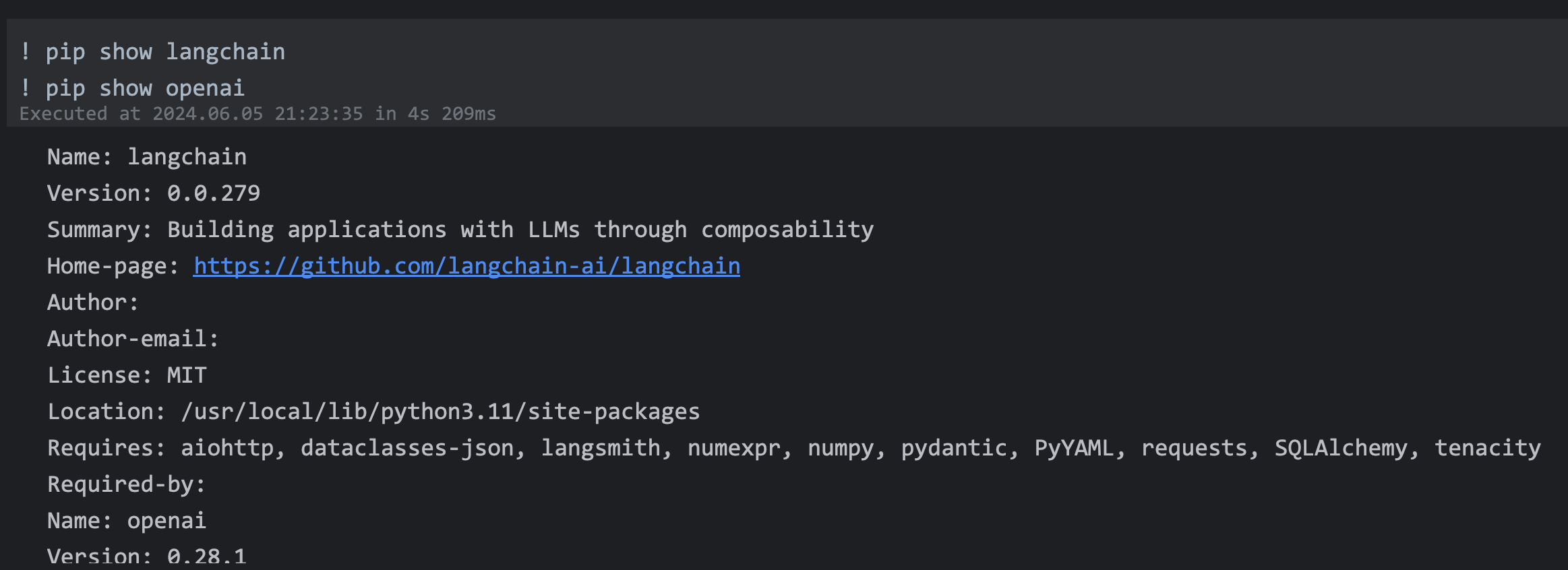 |
| 97 | + |
| 98 | +### openai 官方SDK |
| 99 | + |
| 100 | +```python |
| 101 | +#使用openai的官方sdk |
| 102 | +import openai |
| 103 | +import os |
| 104 | + |
| 105 | +openai.api_base = os.getenv("OPENAI_API_BASE") |
| 106 | +openai.api_key = os.getenv("OPENAI_KEY") |
| 107 | + |
| 108 | +messages = [ |
| 109 | +{"role": "user", "content": "介绍下你自己"} |
| 110 | +] |
| 111 | + |
| 112 | +res = openai.ChatCompletion.create( |
| 113 | +model="gpt-3.5-turbo", |
| 114 | +messages=messages, |
| 115 | +stream=False, |
| 116 | +) |
| 117 | + |
| 118 | +print(res['choices'][0]['message']['content']) |
| 119 | +``` |
| 120 | + |
| 121 | +### 使用langchain调用 |
| 122 | + |
| 123 | +```python |
| 124 | +#hello world |
| 125 | +from langchain.llms import OpenAI |
| 126 | +import os |
| 127 | + |
| 128 | +api_base = os.getenv("OPENAI_API_BASE") |
| 129 | +api_key = os.getenv("OPENAI_KEY") |
| 130 | +llm = OpenAI( |
| 131 | + model="gpt-3.5-turbo-instruct", |
| 132 | + temperature=0, |
| 133 | + openai_api_key=api_key, |
| 134 | + openai_api_base=api_base |
| 135 | + ) |
| 136 | +llm.predict("介绍下你自己") |
| 137 | +``` |
| 138 | + |
| 139 | +### 起名大师 |
| 140 | + |
| 141 | +```python |
| 142 | +#起名大师 |
| 143 | +from langchain.llms import OpenAI |
| 144 | +from langchain.prompts import PromptTemplate |
| 145 | +import os |
| 146 | +api_base = os.getenv("OPENAI_API_BASE") |
| 147 | +api_key = os.getenv("OPENAI_KEY") |
| 148 | +llm = OpenAI( |
| 149 | + model="gpt-3.5-turbo-instruct", |
| 150 | + temperature=0, |
| 151 | + openai_api_key=api_key, |
| 152 | + openai_api_base=api_base |
| 153 | + ) |
| 154 | +prompt = PromptTemplate.from_template("你是一个起名大师,请模仿示例起3个{county}名字,比如男孩经常被叫做{boy},女孩经常被叫做{girl}") |
| 155 | +message = prompt.format(county="中国特色的",boy="狗蛋",girl="翠花") |
| 156 | +print(message) |
| 157 | +llm.predict(message) |
| 158 | +``` |
| 159 | + |
| 160 | +输出: |
| 161 | + |
| 162 | +``` |
| 163 | +'\n\n男孩: 龙飞、铁柱、小虎\n女孩: 玉兰、梅香、小红梅' |
| 164 | +``` |
| 165 | + |
| 166 | +### 格式化输出 |
| 167 | + |
| 168 | +```python |
| 169 | +from langchain.schema import BaseOutputParser |
| 170 | +#自定义class,继承了BaseOutputParser |
| 171 | +class CommaSeparatedListOutputParser(BaseOutputParser): |
| 172 | + """Parse the output of an LLM call to a comma-separated list.""" |
| 173 | + |
| 174 | + |
| 175 | + def parse(self, text: str): |
| 176 | + """Parse the output of an LLM call.""" |
| 177 | + return text.strip().split(", ") |
| 178 | + |
| 179 | +CommaSeparatedListOutputParser().parse("hi, bye") |
| 180 | +``` |
| 181 | + |
| 182 | +``` |
| 183 | +['hi', 'bye'] |
| 184 | +``` |
| 185 | + |
| 186 | +### 完整案例 |
| 187 | + |
| 188 | +```python |
| 189 | +#起名大师,输出格式为一个数组 |
| 190 | +from langchain.llms import OpenAI |
| 191 | +from langchain.prompts import PromptTemplate |
| 192 | +import os |
| 193 | +from langchain.schema import BaseOutputParser |
| 194 | + |
| 195 | +#自定义类 |
| 196 | +class CommaSeparatedListOutputParser(BaseOutputParser): |
| 197 | + """Parse the output of an LLM call to a comma-separated list.""" |
| 198 | + |
| 199 | + def parse(self, text: str): |
| 200 | + """Parse the output of an LLM call.""" |
| 201 | + print(text) |
| 202 | + return text.strip().split(",") |
| 203 | + |
| 204 | + |
| 205 | +api_base = os.getenv("OPENAI_API_BASE") |
| 206 | +api_key = os.getenv("OPENAI_KEY") |
| 207 | +llm = OpenAI( |
| 208 | + model="gpt-3.5-turbo-instruct", |
| 209 | + temperature=0, |
| 210 | + openai_api_key=api_key, |
| 211 | + openai_api_base=api_base |
| 212 | + ) |
| 213 | +prompt = PromptTemplate.from_template("你是一个起名大师,请模仿示例起3个具有{county}特色的名字,示例:男孩常用名{boy},女孩常用名{girl}。请返回以逗号分隔的列表形式。仅返回逗号分隔的列表,不要返回其他内容。") |
| 214 | +message = prompt.format(county="美国男孩",boy="sam",girl="lucy") |
| 215 | +print(message) |
| 216 | +strs = llm.predict(message) |
| 217 | +CommaSeparatedListOutputParser().parse(strs) |
| 218 | +``` |
| 219 | + |
| 220 | +``` |
| 221 | +['jack', ' michael', ' jason'] |
| 222 | +``` |
| 223 | + |
0 commit comments