Inception and Xception model, imported using Keras, after the preprocessing of images have been trained on the dataset.
The details about the Model can be found in the Jupyter Notebooks.
Design of both the Model is similar:
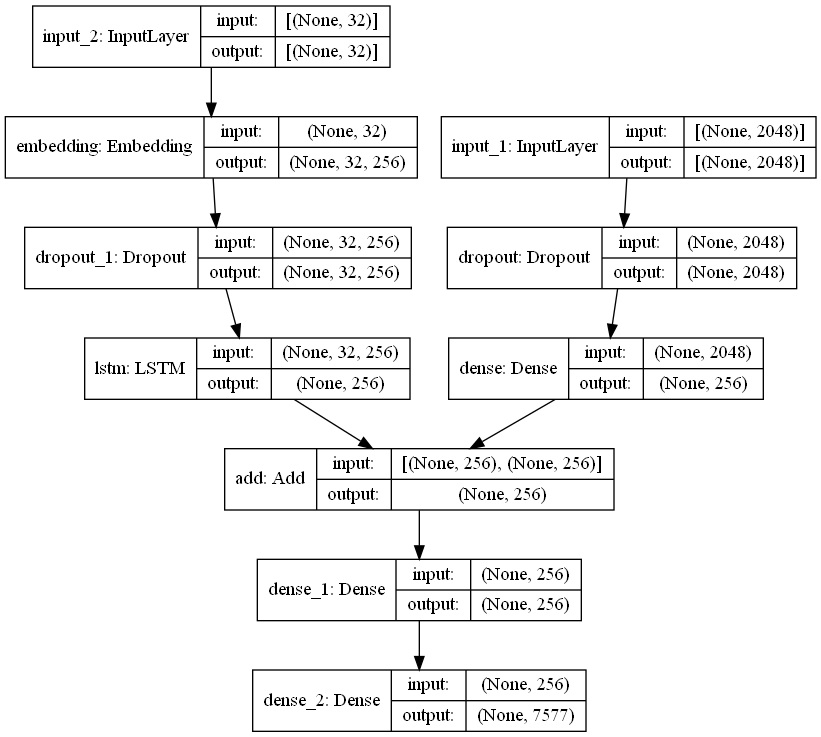
A link to the Models can be found here
We have also used GLoVe.6b word representation model for determining word to word resemblance in captions.
Training is performed on aggregated global word-word co-occurrence statistics from the Dataset.
Here is a Direct Link for the model.