diff --git a/astrbot/core/astr_agent_hooks.py b/astrbot/core/astr_agent_hooks.py
index 1213c418ad..423b7cb5f6 100644
--- a/astrbot/core/astr_agent_hooks.py
+++ b/astrbot/core/astr_agent_hooks.py
@@ -9,6 +9,7 @@
from astrbot.core.astr_agent_context import AstrAgentContext
from astrbot.core.pipeline.context_utils import call_event_hook
from astrbot.core.star.star_handler import EventType
+from astrbot.core.utils.web_search_utils import WEB_SEARCH_REFERENCE_TOOLS
class MainAgentHooks(BaseAgentRunHooks[AstrAgentContext]):
@@ -74,13 +75,7 @@ async def on_tool_end(
platform_name = run_context.context.event.get_platform_name()
if (
platform_name == "webchat"
- and tool.name
- in [
- "web_search_baidu",
- "web_search_tavily",
- "web_search_bocha",
- "web_search_brave",
- ]
+ and tool.name in WEB_SEARCH_REFERENCE_TOOLS
and len(run_context.messages) > 0
and tool_result
and len(tool_result.content)
diff --git a/astrbot/core/astr_main_agent.py b/astrbot/core/astr_main_agent.py
index 3916215e5b..5862bfa951 100644
--- a/astrbot/core/astr_main_agent.py
+++ b/astrbot/core/astr_main_agent.py
@@ -85,6 +85,9 @@
BaiduWebSearchTool,
BochaWebSearchTool,
BraveWebSearchTool,
+ ExaExtractWebPageTool,
+ ExaFindSimilarTool,
+ ExaWebSearchTool,
FirecrawlExtractWebPageTool,
FirecrawlWebSearchTool,
TavilyExtractWebPageTool,
@@ -1116,6 +1119,10 @@ async def _apply_web_search_tools(
req.func_tool.add_tool(tool_mgr.get_builtin_tool(FirecrawlExtractWebPageTool))
elif provider == "baidu_ai_search":
req.func_tool.add_tool(tool_mgr.get_builtin_tool(BaiduWebSearchTool))
+ elif provider == "exa":
+ req.func_tool.add_tool(tool_mgr.get_builtin_tool(ExaWebSearchTool))
+ req.func_tool.add_tool(tool_mgr.get_builtin_tool(ExaExtractWebPageTool))
+ req.func_tool.add_tool(tool_mgr.get_builtin_tool(ExaFindSimilarTool))
def _get_compress_provider(
diff --git a/astrbot/core/config/default.py b/astrbot/core/config/default.py
index 2b8fce9d34..31f5fe68d1 100644
--- a/astrbot/core/config/default.py
+++ b/astrbot/core/config/default.py
@@ -108,9 +108,12 @@
"web_search": False,
"websearch_provider": "tavily",
"websearch_tavily_key": [],
+ "websearch_tavily_base_url": "https://api.tavily.com",
"websearch_bocha_key": [],
"websearch_brave_key": [],
"websearch_baidu_app_builder_key": "",
+ "websearch_exa_key": [],
+ "websearch_exa_base_url": "https://api.exa.ai",
"web_search_link": False,
"display_reasoning_text": False,
"identifier": False,
@@ -3190,6 +3193,7 @@
"baidu_ai_search",
"bocha",
"brave",
+ "exa",
"firecrawl",
],
"condition": {
@@ -3244,6 +3248,34 @@
"provider_settings.websearch_provider": "baidu_ai_search",
},
},
+ "provider_settings.websearch_tavily_base_url": {
+ "description": "Tavily API Base URL",
+ "type": "string",
+ "hint": "默认为 https://api.tavily.com,可改为代理地址。",
+ "condition": {
+ "provider_settings.websearch_provider": "tavily",
+ "provider_settings.web_search": True,
+ },
+ },
+ "provider_settings.websearch_exa_key": {
+ "description": "Exa API Key",
+ "type": "list",
+ "items": {"type": "string"},
+ "hint": "可添加多个 Key 进行轮询。",
+ "condition": {
+ "provider_settings.websearch_provider": "exa",
+ "provider_settings.web_search": True,
+ },
+ },
+ "provider_settings.websearch_exa_base_url": {
+ "description": "Exa API Base URL",
+ "type": "string",
+ "hint": "默认为 https://api.exa.ai,可改为代理地址。",
+ "condition": {
+ "provider_settings.websearch_provider": "exa",
+ "provider_settings.web_search": True,
+ },
+ },
"provider_settings.web_search_link": {
"description": "显示来源引用",
"type": "bool",
diff --git a/astrbot/core/knowledge_base/kb_helper.py b/astrbot/core/knowledge_base/kb_helper.py
index 1f867ec27d..38ef34e12c 100644
--- a/astrbot/core/knowledge_base/kb_helper.py
+++ b/astrbot/core/knowledge_base/kb_helper.py
@@ -613,12 +613,18 @@ async def upload_from_url(
"Error: Tavily API key is not configured in provider_settings."
)
+ tavily_base_url = config.get("provider_settings", {}).get(
+ "websearch_tavily_base_url", "https://api.tavily.com"
+ )
+
# 阶段1: 从 URL 提取内容
if progress_callback:
await progress_callback("extracting", 0, 100)
try:
- text_content = await extract_text_from_url(url, tavily_keys)
+ text_content = await extract_text_from_url(
+ url, tavily_keys, tavily_base_url
+ )
except Exception as e:
logger.error(f"Failed to extract content from URL {url}: {e}")
raise OSError(f"Failed to extract content from URL {url}: {e}") from e
diff --git a/astrbot/core/knowledge_base/parsers/url_parser.py b/astrbot/core/knowledge_base/parsers/url_parser.py
index 2867164a96..a8d6b3694e 100644
--- a/astrbot/core/knowledge_base/parsers/url_parser.py
+++ b/astrbot/core/knowledge_base/parsers/url_parser.py
@@ -2,16 +2,21 @@
import aiohttp
+from astrbot.core.utils.web_search_utils import normalize_web_search_base_url
+
class URLExtractor:
"""URL 内容提取器,封装了 Tavily API 调用和密钥管理"""
- def __init__(self, tavily_keys: list[str]) -> None:
+ def __init__(
+ self, tavily_keys: list[str], tavily_base_url: str = "https://api.tavily.com"
+ ) -> None:
"""
初始化 URL 提取器
Args:
tavily_keys: Tavily API 密钥列表
+ tavily_base_url: Tavily API 基础 URL
"""
if not tavily_keys:
raise ValueError("Error: Tavily API keys are not configured.")
@@ -19,6 +24,12 @@ def __init__(self, tavily_keys: list[str]) -> None:
self.tavily_keys = tavily_keys
self.tavily_key_index = 0
self.tavily_key_lock = asyncio.Lock()
+ self.tavily_base_url = normalize_web_search_base_url(
+ tavily_base_url,
+ default="https://api.tavily.com",
+ provider_name="Tavily",
+ disallowed_path_suffixes=("search", "extract"),
+ )
async def _get_tavily_key(self) -> str:
"""并发安全的从列表中获取并轮换Tavily API密钥。"""
@@ -47,7 +58,7 @@ async def extract_text_from_url(self, url: str) -> str:
raise ValueError("Error: url must be a non-empty string.")
tavily_key = await self._get_tavily_key()
- api_url = "https://api.tavily.com/extract"
+ api_url = f"{self.tavily_base_url}/extract"
headers = {
"Authorization": f"Bearer {tavily_key}",
"Content-Type": "application/json",
@@ -69,7 +80,10 @@ async def extract_text_from_url(self, url: str) -> str:
if response.status != 200:
reason = await response.text()
raise OSError(
- f"Tavily web extraction failed: {reason}, status: {response.status}"
+ f"Tavily web extraction failed for URL {api_url}: "
+ f"{reason}, status: {response.status}. If you configured "
+ "a Tavily API Base URL, make sure it is a base URL or "
+ "proxy prefix rather than a specific endpoint path."
)
data = await response.json()
@@ -88,16 +102,19 @@ async def extract_text_from_url(self, url: str) -> str:
# 为了向后兼容,提供一个简单的函数接口
-async def extract_text_from_url(url: str, tavily_keys: list[str]) -> str:
+async def extract_text_from_url(
+ url: str, tavily_keys: list[str], tavily_base_url: str = "https://api.tavily.com"
+) -> str:
"""
简单的函数接口,用于从 URL 提取文本内容
Args:
url: 要提取内容的网页 URL
tavily_keys: Tavily API 密钥列表
+ tavily_base_url: Tavily API 基础 URL
Returns:
提取的文本内容
"""
- extractor = URLExtractor(tavily_keys)
+ extractor = URLExtractor(tavily_keys, tavily_base_url)
return await extractor.extract_text_from_url(url)
diff --git a/astrbot/core/tools/web_search_tools.py b/astrbot/core/tools/web_search_tools.py
index ebd13d0102..73844215bb 100644
--- a/astrbot/core/tools/web_search_tools.py
+++ b/astrbot/core/tools/web_search_tools.py
@@ -12,6 +12,9 @@
from astrbot.core.agent.tool import FunctionTool, ToolExecResult
from astrbot.core.astr_agent_context import AstrAgentContext
from astrbot.core.tools.registry import builtin_tool
+from astrbot.core.utils.web_search_utils import normalize_web_search_base_url
+
+MIN_WEB_SEARCH_TIMEOUT = 30
WEB_SEARCH_TOOL_NAMES = [
"web_search_baidu",
@@ -19,6 +22,9 @@
"tavily_extract_web_page",
"web_search_bocha",
"web_search_brave",
+ "web_search_exa",
+ "exa_extract_web_page",
+ "exa_find_similar",
"web_search_firecrawl",
"firecrawl_extract_web_page",
]
@@ -42,6 +48,19 @@
"provider_settings.web_search": True,
"provider_settings.websearch_provider": "baidu_ai_search",
}
+_EXA_WEB_SEARCH_TOOL_CONFIG = {
+ "provider_settings.web_search": True,
+ "provider_settings.websearch_provider": "exa",
+}
+_EXA_SEARCH_TYPES = (
+ "auto",
+ "fast",
+ "deep",
+ "deep-lite",
+ "deep-reasoning",
+ "instant",
+ "neural",
+)
@std_dataclass
@@ -75,6 +94,7 @@ async def get(self, provider_settings: dict) -> str:
_TAVILY_KEY_ROTATOR = _KeyRotator("websearch_tavily_key", "Tavily")
_BOCHA_KEY_ROTATOR = _KeyRotator("websearch_bocha_key", "BoCha")
_BRAVE_KEY_ROTATOR = _KeyRotator("websearch_brave_key", "Brave")
+_EXA_KEY_ROTATOR = _KeyRotator("websearch_exa_key", "Exa")
_FIRECRAWL_KEY_ROTATOR = _KeyRotator("websearch_firecrawl_key", "Firecrawl")
@@ -98,6 +118,7 @@ def normalize_legacy_web_search_config(cfg) -> None:
"websearch_tavily_key",
"websearch_bocha_key",
"websearch_brave_key",
+ "websearch_exa_key",
"websearch_firecrawl_key",
):
value = provider_settings.get(setting_name)
@@ -117,13 +138,63 @@ def _get_runtime(context) -> tuple[dict, dict, str]:
return cfg, provider_settings, event.unified_msg_origin
+def _normalize_timeout(timeout: int | float | str | None) -> aiohttp.ClientTimeout:
+ try:
+ timeout_value = int(timeout) if timeout is not None else MIN_WEB_SEARCH_TIMEOUT
+ except (TypeError, ValueError):
+ timeout_value = MIN_WEB_SEARCH_TIMEOUT
+ return aiohttp.ClientTimeout(total=max(timeout_value, MIN_WEB_SEARCH_TIMEOUT))
+
+
+def _normalize_count(
+ value: int | float | str | None,
+ *,
+ default: int,
+ minimum: int,
+ maximum: int,
+) -> int:
+ try:
+ count = int(value) if value is not None else default
+ except (TypeError, ValueError):
+ count = default
+ return max(minimum, min(count, maximum))
+
+
def _cache_favicon(url: str, favicon: str | None) -> None:
if favicon:
sp.temporary_cache["_ws_favicon"][url] = favicon
+def _format_provider_request_error(
+ provider_name: str, action: str, url: str, reason: str, status: int
+) -> str:
+ return (
+ f"{provider_name} {action} failed for URL {url}: {reason}, status: {status}. "
+ "If you configured an API Base URL, make sure it is a base URL or proxy "
+ "prefix rather than a specific endpoint path."
+ )
+
+
+def _get_tavily_base_url(provider_settings: dict) -> str:
+ return normalize_web_search_base_url(
+ provider_settings.get("websearch_tavily_base_url"),
+ default="https://api.tavily.com",
+ provider_name="Tavily",
+ disallowed_path_suffixes=("search", "extract"),
+ )
+
+
+def _get_exa_base_url(provider_settings: dict) -> str:
+ return normalize_web_search_base_url(
+ provider_settings.get("websearch_exa_base_url"),
+ default="https://api.exa.ai",
+ provider_name="Exa",
+ disallowed_path_suffixes=("search", "contents", "findSimilar"),
+ )
+
+
def _search_result_payload(results: list[SearchResult]) -> str:
- ref_uuid = str(uuid.uuid4())[:4]
+ ref_uuid = uuid.uuid4().hex
ret_ls = []
for idx, result in enumerate(results, 1):
index = f"{ref_uuid}.{idx}"
@@ -139,25 +210,54 @@ def _search_result_payload(results: list[SearchResult]) -> str:
return json.dumps({"results": ret_ls}, ensure_ascii=False)
+def _format_exa_contents_status_error(statuses: list[dict]) -> str | None:
+ failed_statuses = [
+ status
+ for status in statuses
+ if status.get("status") and status["status"] != "success"
+ ]
+ if not failed_statuses:
+ return None
+
+ errors = []
+ for status in failed_statuses:
+ error = status.get("error") or {}
+ details = error.get("tag") or "unknown error"
+ http_status = error.get("httpStatusCode")
+ if http_status is not None:
+ details = f"{details} (HTTP {http_status})"
+ errors.append(f"{status.get('id', 'unknown URL')}: {details}")
+ return "Error: Exa content extraction failed: " + "; ".join(errors)
+
+
async def _tavily_search(
provider_settings: dict,
payload: dict,
+ timeout: int = MIN_WEB_SEARCH_TIMEOUT,
) -> list[SearchResult]:
tavily_key = await _TAVILY_KEY_ROTATOR.get(provider_settings)
+ url = f"{_get_tavily_base_url(provider_settings)}/search"
header = {
"Authorization": f"Bearer {tavily_key}",
"Content-Type": "application/json",
}
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.post(
- "https://api.tavily.com/search",
+ url,
json=payload,
headers=header,
+ timeout=_normalize_timeout(timeout),
) as response:
if response.status != 200:
reason = await response.text()
raise Exception(
- f"Tavily web search failed: {reason}, status: {response.status}",
+ _format_provider_request_error(
+ "Tavily",
+ "web search",
+ url,
+ reason,
+ response.status,
+ )
)
data = await response.json()
return [
@@ -171,22 +271,34 @@ async def _tavily_search(
]
-async def _tavily_extract(provider_settings: dict, payload: dict) -> list[dict]:
+async def _tavily_extract(
+ provider_settings: dict,
+ payload: dict,
+ timeout: int = MIN_WEB_SEARCH_TIMEOUT,
+) -> list[dict]:
tavily_key = await _TAVILY_KEY_ROTATOR.get(provider_settings)
+ url = f"{_get_tavily_base_url(provider_settings)}/extract"
header = {
"Authorization": f"Bearer {tavily_key}",
"Content-Type": "application/json",
}
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.post(
- "https://api.tavily.com/extract",
+ url,
json=payload,
headers=header,
+ timeout=_normalize_timeout(timeout),
) as response:
if response.status != 200:
reason = await response.text()
raise Exception(
- f"Tavily web search failed: {reason}, status: {response.status}",
+ _format_provider_request_error(
+ "Tavily",
+ "content extraction",
+ url,
+ reason,
+ response.status,
+ )
)
data = await response.json()
results: list[dict] = data.get("results", [])
@@ -200,6 +312,7 @@ async def _tavily_extract(provider_settings: dict, payload: dict) -> list[dict]:
async def _bocha_search(
provider_settings: dict,
payload: dict,
+ timeout: int = MIN_WEB_SEARCH_TIMEOUT,
) -> list[SearchResult]:
bocha_key = await _BOCHA_KEY_ROTATOR.get(provider_settings)
header = {
@@ -215,11 +328,12 @@ async def _bocha_search(
"https://api.bochaai.com/v1/web-search",
json=payload,
headers=header,
+ timeout=_normalize_timeout(timeout),
) as response:
if response.status != 200:
reason = await response.text()
raise Exception(
- f"BoCha web search failed: {reason}, status: {response.status}",
+ f"BoCha web search failed: {reason}, status: {response.status}"
)
data = await response.json()
rows = data["data"]["webPages"]["value"]
@@ -237,6 +351,7 @@ async def _bocha_search(
async def _brave_search(
provider_settings: dict,
payload: dict,
+ timeout: int = MIN_WEB_SEARCH_TIMEOUT,
) -> list[SearchResult]:
brave_key = await _BRAVE_KEY_ROTATOR.get(provider_settings)
header = {
@@ -248,11 +363,12 @@ async def _brave_search(
"https://api.search.brave.com/res/v1/web/search",
params=payload,
headers=header,
+ timeout=_normalize_timeout(timeout),
) as response:
if response.status != 200:
reason = await response.text()
raise Exception(
- f"Brave web search failed: {reason}, status: {response.status}",
+ f"Brave web search failed: {reason}, status: {response.status}"
)
data = await response.json()
rows = data.get("web", {}).get("results", [])
@@ -335,6 +451,7 @@ async def _firecrawl_scrape(provider_settings: dict, payload: dict) -> dict:
async def _baidu_search(
provider_settings: dict,
payload: dict,
+ timeout: int = MIN_WEB_SEARCH_TIMEOUT,
) -> list[SearchResult]:
api_key = provider_settings.get("websearch_baidu_app_builder_key", "")
if not api_key:
@@ -345,16 +462,18 @@ async def _baidu_search(
"X-Appbuilder-Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
+ url = "https://qianfan.baidubce.com/v2/ai_search/web_search"
async with aiohttp.ClientSession(trust_env=True) as session:
async with session.post(
- "https://qianfan.baidubce.com/v2/ai_search/web_search",
+ url,
json=payload,
headers=headers,
+ timeout=_normalize_timeout(timeout),
) as response:
if response.status != 200:
reason = await response.text()
raise Exception(
- f"Baidu AI Search failed: {reason}, status: {response.status}",
+ f"Baidu AI Search failed: {reason}, status: {response.status}"
)
data = await response.json()
references = data.get("references", [])
@@ -370,6 +489,126 @@ async def _baidu_search(
]
+async def _exa_search(
+ provider_settings: dict,
+ payload: dict,
+ timeout: int = MIN_WEB_SEARCH_TIMEOUT,
+) -> list[SearchResult]:
+ exa_key = await _EXA_KEY_ROTATOR.get(provider_settings)
+ url = f"{_get_exa_base_url(provider_settings)}/search"
+ header = {
+ "x-api-key": exa_key,
+ "Content-Type": "application/json",
+ }
+ async with aiohttp.ClientSession(trust_env=True) as session:
+ async with session.post(
+ url,
+ json=payload,
+ headers=header,
+ timeout=_normalize_timeout(timeout),
+ ) as response:
+ if response.status != 200:
+ reason = await response.text()
+ raise Exception(
+ _format_provider_request_error(
+ "Exa",
+ "web search",
+ url,
+ reason,
+ response.status,
+ )
+ )
+ data = await response.json()
+ return [
+ SearchResult(
+ title=item.get("title", ""),
+ url=item.get("url", ""),
+ snippet=(item.get("text") or "")[:500],
+ favicon=item.get("favicon"),
+ )
+ for item in data.get("results", [])
+ ]
+
+
+async def _exa_extract(
+ provider_settings: dict,
+ payload: dict,
+ timeout: int = MIN_WEB_SEARCH_TIMEOUT,
+) -> list[dict]:
+ exa_key = await _EXA_KEY_ROTATOR.get(provider_settings)
+ url = f"{_get_exa_base_url(provider_settings)}/contents"
+ header = {
+ "x-api-key": exa_key,
+ "Content-Type": "application/json",
+ }
+ async with aiohttp.ClientSession(trust_env=True) as session:
+ async with session.post(
+ url,
+ json=payload,
+ headers=header,
+ timeout=_normalize_timeout(timeout),
+ ) as response:
+ if response.status != 200:
+ reason = await response.text()
+ raise Exception(
+ _format_provider_request_error(
+ "Exa",
+ "content extraction",
+ url,
+ reason,
+ response.status,
+ )
+ )
+ data = await response.json()
+ status_error = _format_exa_contents_status_error(
+ data.get("statuses", []),
+ )
+ if status_error:
+ raise ValueError(status_error)
+ return data.get("results", [])
+
+
+async def _exa_find_similar(
+ provider_settings: dict,
+ payload: dict,
+ timeout: int = MIN_WEB_SEARCH_TIMEOUT,
+) -> list[SearchResult]:
+ exa_key = await _EXA_KEY_ROTATOR.get(provider_settings)
+ url = f"{_get_exa_base_url(provider_settings)}/findSimilar"
+ header = {
+ "x-api-key": exa_key,
+ "Content-Type": "application/json",
+ }
+ async with aiohttp.ClientSession(trust_env=True) as session:
+ async with session.post(
+ url,
+ json=payload,
+ headers=header,
+ timeout=_normalize_timeout(timeout),
+ ) as response:
+ if response.status != 200:
+ reason = await response.text()
+ raise Exception(
+ _format_provider_request_error(
+ "Exa",
+ "find similar",
+ url,
+ reason,
+ response.status,
+ )
+ )
+ data = await response.json()
+ return [
+ SearchResult(
+ title=item.get("title", ""),
+ url=item.get("url", ""),
+ snippet=(item.get("text") or "")[:500],
+ favicon=item.get("favicon"),
+ )
+ for item in data.get("results", [])
+ ]
+
+
@builtin_tool(config=_TAVILY_WEB_SEARCH_TOOL_CONFIG)
@pydantic_dataclass
class TavilyWebSearchTool(FunctionTool[AstrAgentContext]):
@@ -411,6 +650,10 @@ class TavilyWebSearchTool(FunctionTool[AstrAgentContext]):
"type": "string",
"description": "Optional. The end date for the search results in the format YYYY-MM-DD.",
},
+ "timeout": {
+ "type": "integer",
+ "description": "Optional. Request timeout in seconds. Minimum is 30. Default is 30.",
+ },
},
"required": ["query"],
}
@@ -447,7 +690,11 @@ async def call(self, context, **kwargs) -> ToolExecResult:
if kwargs.get("end_date"):
payload["end_date"] = kwargs["end_date"]
- results = await _tavily_search(provider_settings, payload)
+ results = await _tavily_search(
+ provider_settings,
+ payload,
+ timeout=kwargs.get("timeout", MIN_WEB_SEARCH_TIMEOUT),
+ )
if not results:
return "Error: Tavily web searcher does not return any results."
return _search_result_payload(results)
@@ -470,6 +717,10 @@ class TavilyExtractWebPageTool(FunctionTool[AstrAgentContext]):
"type": "string",
"description": 'Optional. The depth of the extraction, must be one of "basic", "advanced". Default is "basic".',
},
+ "timeout": {
+ "type": "integer",
+ "description": "Optional. Request timeout in seconds. Minimum is 30. Default is 30.",
+ },
},
"required": ["url"],
}
@@ -491,6 +742,7 @@ async def call(self, context, **kwargs) -> ToolExecResult:
results = await _tavily_extract(
provider_settings,
{"urls": [url], "extract_depth": extract_depth},
+ timeout=kwargs.get("timeout", MIN_WEB_SEARCH_TIMEOUT),
)
ret_ls = []
for result in results:
@@ -500,6 +752,184 @@ async def call(self, context, **kwargs) -> ToolExecResult:
return ret or "Error: Tavily web searcher does not return any results."
+@builtin_tool(config=_EXA_WEB_SEARCH_TOOL_CONFIG)
+@pydantic_dataclass
+class ExaWebSearchTool(FunctionTool[AstrAgentContext]):
+ name: str = "web_search_exa"
+ description: str = (
+ "A semantic web search tool based on Exa. Use it for general search, "
+ "vertical search, and concept-oriented retrieval."
+ )
+ parameters: dict = Field(
+ default_factory=lambda: {
+ "type": "object",
+ "properties": {
+ "query": {"type": "string", "description": "Required. Search query."},
+ "max_results": {
+ "type": "integer",
+ "description": "Optional. Maximum number of results to return. Default is 10. Range is 1-100.",
+ },
+ "search_type": {
+ "type": "string",
+ "description": 'Optional. Search type. Must be one of "auto", "fast", "deep", "deep-lite", "deep-reasoning", "instant", "neural". Default is "auto".',
+ },
+ "category": {
+ "type": "string",
+ "description": 'Optional. Vertical search category. Supported values: "company", "people", "research paper", "news", "personal site", "financial report".',
+ },
+ "timeout": {
+ "type": "integer",
+ "description": "Optional. Request timeout in seconds. Minimum is 30. Default is 30.",
+ },
+ },
+ "required": ["query"],
+ }
+ )
+
+ async def call(self, context, **kwargs) -> ToolExecResult:
+ _, provider_settings, _ = _get_runtime(context)
+ if not provider_settings.get("websearch_exa_key", []):
+ return "Error: Exa API key is not configured in AstrBot."
+
+ search_type = str(kwargs.get("search_type", "auto")).strip().lower()
+ if search_type not in _EXA_SEARCH_TYPES:
+ search_type = "auto"
+
+ max_results = _normalize_count(
+ kwargs.get("max_results"),
+ default=10,
+ minimum=1,
+ maximum=100,
+ )
+ payload = {
+ "query": kwargs["query"],
+ "numResults": max_results,
+ "type": search_type,
+ "contents": {"text": {"maxCharacters": 500}},
+ }
+
+ category = str(kwargs.get("category", "")).strip()
+ if category in (
+ "company",
+ "people",
+ "research paper",
+ "news",
+ "personal site",
+ "financial report",
+ ):
+ payload["category"] = category
+
+ results = await _exa_search(
+ provider_settings,
+ payload,
+ timeout=kwargs.get("timeout", MIN_WEB_SEARCH_TIMEOUT),
+ )
+ if not results:
+ return "Error: Exa web searcher does not return any results."
+ return _search_result_payload(results)
+
+
+@builtin_tool(config=_EXA_WEB_SEARCH_TOOL_CONFIG)
+@pydantic_dataclass
+class ExaExtractWebPageTool(FunctionTool[AstrAgentContext]):
+ name: str = "exa_extract_web_page"
+ description: str = "Extract the content of a web page using Exa."
+ parameters: dict = Field(
+ default_factory=lambda: {
+ "type": "object",
+ "properties": {
+ "url": {
+ "type": "string",
+ "description": "Required. A URL to extract content from.",
+ },
+ "timeout": {
+ "type": "integer",
+ "description": "Optional. Request timeout in seconds. Minimum is 30. Default is 30.",
+ },
+ },
+ "required": ["url"],
+ }
+ )
+
+ async def call(self, context, **kwargs) -> ToolExecResult:
+ _, provider_settings, _ = _get_runtime(context)
+ if not provider_settings.get("websearch_exa_key", []):
+ return "Error: Exa API key is not configured in AstrBot."
+
+ url = str(kwargs.get("url", "")).strip()
+ if not url:
+ return "Error: url must be a non-empty string."
+
+ results = await _exa_extract(
+ provider_settings,
+ {"urls": [url], "text": True},
+ timeout=kwargs.get("timeout", MIN_WEB_SEARCH_TIMEOUT),
+ )
+ if not results:
+ return "Error: Exa content extraction does not return any results."
+
+ ret_ls = []
+ for result in results:
+ ret_ls.append(f"URL: {result.get('url', 'No URL')}")
+ ret_ls.append(f"Content: {result.get('text', 'No content')}")
+ ret = "\n".join(ret_ls)
+ return ret or "Error: Exa content extraction does not return any results."
+
+
+@builtin_tool(config=_EXA_WEB_SEARCH_TOOL_CONFIG)
+@pydantic_dataclass
+class ExaFindSimilarTool(FunctionTool[AstrAgentContext]):
+ name: str = "exa_find_similar"
+ description: str = "Find semantically similar pages to a given URL using Exa."
+ parameters: dict = Field(
+ default_factory=lambda: {
+ "type": "object",
+ "properties": {
+ "url": {
+ "type": "string",
+ "description": "Required. The URL to find similar content for.",
+ },
+ "max_results": {
+ "type": "integer",
+ "description": "Optional. Maximum number of results to return. Default is 10. Range is 1-100.",
+ },
+ "timeout": {
+ "type": "integer",
+ "description": "Optional. Request timeout in seconds. Minimum is 30. Default is 30.",
+ },
+ },
+ "required": ["url"],
+ }
+ )
+
+ async def call(self, context, **kwargs) -> ToolExecResult:
+ _, provider_settings, _ = _get_runtime(context)
+ if not provider_settings.get("websearch_exa_key", []):
+ return "Error: Exa API key is not configured in AstrBot."
+
+ url = str(kwargs.get("url", "")).strip()
+ if not url:
+ return "Error: url must be a non-empty string."
+
+ results = await _exa_find_similar(
+ provider_settings,
+ {
+ "url": url,
+ "numResults": _normalize_count(
+ kwargs.get("max_results"),
+ default=10,
+ minimum=1,
+ maximum=100,
+ ),
+ "contents": {"text": {"maxCharacters": 500}},
+ },
+ timeout=kwargs.get("timeout", MIN_WEB_SEARCH_TIMEOUT),
+ )
+ if not results:
+ return "Error: Exa find similar does not return any results."
+ return _search_result_payload(results)
+
+
@builtin_tool(config=_BOCHA_WEB_SEARCH_TOOL_CONFIG)
@pydantic_dataclass
class BochaWebSearchTool(FunctionTool[AstrAgentContext]):
@@ -536,6 +966,10 @@ class BochaWebSearchTool(FunctionTool[AstrAgentContext]):
"type": "integer",
"description": "Optional. Number of search results to return. Range: 1-50.",
},
+ "timeout": {
+ "type": "integer",
+ "description": "Optional. Request timeout in seconds. Minimum is 30. Default is 30.",
+ },
},
"required": ["query"],
}
@@ -558,7 +992,11 @@ async def call(self, context, **kwargs) -> ToolExecResult:
if kwargs.get("exclude"):
payload["exclude"] = kwargs["exclude"]
- results = await _bocha_search(provider_settings, payload)
+ results = await _bocha_search(
+ provider_settings,
+ payload,
+ timeout=kwargs.get("timeout", MIN_WEB_SEARCH_TIMEOUT),
+ )
if not results:
return "Error: BoCha web searcher does not return any results."
return _search_result_payload(results)
@@ -590,6 +1028,10 @@ class BraveWebSearchTool(FunctionTool[AstrAgentContext]):
"type": "string",
"description": 'Optional. One of "day", "week", "month", "year".',
},
+ "timeout": {
+ "type": "integer",
+ "description": "Optional. Request timeout in seconds. Minimum is 30. Default is 30.",
+ },
},
"required": ["query"],
}
@@ -616,7 +1058,11 @@ async def call(self, context, **kwargs) -> ToolExecResult:
if freshness in ["day", "week", "month", "year"]:
payload["freshness"] = freshness
- results = await _brave_search(provider_settings, payload)
+ results = await _brave_search(
+ provider_settings,
+ payload,
+ timeout=kwargs.get("timeout", MIN_WEB_SEARCH_TIMEOUT),
+ )
if not results:
return "Error: Brave web searcher does not return any results."
return _search_result_payload(results)
@@ -765,6 +1211,10 @@ class BaiduWebSearchTool(FunctionTool[AstrAgentContext]):
"type": "string",
"description": "Optional. Restrict search to specific sites, separated by commas.",
},
+ "timeout": {
+ "type": "integer",
+ "description": "Optional. Request timeout in seconds. Minimum is 30. Default is 30.",
+ },
},
"required": ["query"],
}
@@ -797,7 +1247,11 @@ async def call(self, context, **kwargs) -> ToolExecResult:
if sites:
payload["search_filter"] = {"match": {"site": sites[:100]}}
- results = await _baidu_search(provider_settings, payload)
+ results = await _baidu_search(
+ provider_settings,
+ payload,
+ timeout=kwargs.get("timeout", MIN_WEB_SEARCH_TIMEOUT),
+ )
if not results:
return "Error: Baidu AI Search does not return any results."
return _search_result_payload(results)
@@ -807,6 +1261,11 @@ async def call(self, context, **kwargs) -> ToolExecResult:
"BaiduWebSearchTool",
"BochaWebSearchTool",
"BraveWebSearchTool",
+ "ExaExtractWebPageTool",
+ "ExaFindSimilarTool",
+ "ExaWebSearchTool",
+ "FirecrawlExtractWebPageTool",
+ "FirecrawlWebSearchTool",
"TavilyExtractWebPageTool",
"TavilyWebSearchTool",
"WEB_SEARCH_TOOL_NAMES",
diff --git a/astrbot/core/utils/web_search_utils.py b/astrbot/core/utils/web_search_utils.py
new file mode 100644
index 0000000000..680cd1b58a
--- /dev/null
+++ b/astrbot/core/utils/web_search_utils.py
@@ -0,0 +1,146 @@
+import json
+import re
+from typing import Any
+from urllib.parse import urlparse
+
+WEB_SEARCH_REFERENCE_TOOLS = (
+ "web_search_baidu",
+ "web_search_tavily",
+ "web_search_bocha",
+ "web_search_brave",
+ "web_search_exa",
+ "exa_find_similar",
+)
+
+
+def normalize_web_search_base_url(
+ base_url: str | None,
+ *,
+ default: str,
+ provider_name: str,
+ disallowed_path_suffixes: tuple[str, ...] = (),
+) -> str:
+ normalized = (base_url or "").strip()
+ if not normalized:
+ normalized = default
+ normalized = normalized.rstrip("/")
+
+ parsed = urlparse(normalized)
+ if parsed.scheme not in {"http", "https"} or not parsed.netloc:
+ raise ValueError(
+ f"Error: {provider_name} API Base URL must start with http:// or "
+ f"https://. Proxy base paths are allowed. Received: {normalized!r}.",
+ )
+
+ last_path_segment = parsed.path.rstrip("/").rsplit("/", 1)[-1].lower()
+ invalid_suffixes = {
+ suffix.strip("/").lower()
+ for suffix in disallowed_path_suffixes
+ if suffix and suffix.strip("/")
+ }
+ if last_path_segment and last_path_segment in invalid_suffixes:
+ raise ValueError(
+ f"Error: {provider_name} API Base URL must be a base URL or proxy "
+ f"prefix, not a specific endpoint path. Received: {normalized!r}.",
+ )
+ return normalized
+
+
+def _iter_web_search_result_items(
+ accumulated_parts: list[dict[str, Any]],
+):
+ for part in accumulated_parts:
+ if part.get("type") != "tool_call" or not part.get("tool_calls"):
+ continue
+
+ for tool_call in part["tool_calls"]:
+ if tool_call.get(
+ "name"
+ ) not in WEB_SEARCH_REFERENCE_TOOLS or not tool_call.get("result"):
+ continue
+
+ result = tool_call["result"]
+ try:
+ result_data = json.loads(result) if isinstance(result, str) else result
+ except json.JSONDecodeError:
+ continue
+
+ if not isinstance(result_data, dict):
+ continue
+
+ for item in result_data.get("results", []):
+ if isinstance(item, dict):
+ yield item
+
+
+def _extract_ref_indices(accumulated_text: str) -> list[str]:
+ ref_indices: list[str] = []
+ seen_indices: set[str] = set()
+
+ for match in re.finditer(r"[(.*?)]", accumulated_text):
+ ref_index = match.group(1).strip()
+ if not ref_index or ref_index in seen_indices:
+ continue
+ ref_indices.append(ref_index)
+ seen_indices.add(ref_index)
+
+ return ref_indices
+
+
+def collect_web_search_ref_items(
+ accumulated_parts: list[dict[str, Any]],
+ favicon_cache: dict[str, str] | None = None,
+) -> list[dict[str, Any]]:
+ web_search_refs: list[dict[str, Any]] = []
+ seen_indices: set[str] = set()
+
+ for item in _iter_web_search_result_items(accumulated_parts):
+ ref_index = item.get("index")
+ if not ref_index or ref_index in seen_indices:
+ continue
+
+ payload = {
+ "index": ref_index,
+ "url": item.get("url"),
+ "title": item.get("title"),
+ "snippet": item.get("snippet"),
+ }
+ if favicon_cache and payload["url"] in favicon_cache:
+ payload["favicon"] = favicon_cache[payload["url"]]
+
+ web_search_refs.append(payload)
+ seen_indices.add(ref_index)
+
+ return web_search_refs
+
+
+def build_web_search_refs(
+ accumulated_text: str,
+ accumulated_parts: list[dict[str, Any]],
+ favicon_cache: dict[str, str] | None = None,
+) -> dict:
+ ordered_refs = collect_web_search_ref_items(accumulated_parts, favicon_cache)
+ if not ordered_refs:
+ return {}
+
+ refs_by_index = {ref["index"]: ref for ref in ordered_refs}
+ ref_indices = _extract_ref_indices(accumulated_text)
+ used_refs = [refs_by_index[idx] for idx in ref_indices if idx in refs_by_index]
+
+ if not used_refs:
+ used_refs = ordered_refs
+
+ return {"used": used_refs}
+
+
+def collect_web_search_results(accumulated_parts: list[dict[str, Any]]) -> dict:
+ web_search_results = {}
+
+ for ref in collect_web_search_ref_items(accumulated_parts):
+ web_search_results[ref["index"]] = {
+ "url": ref.get("url"),
+ "title": ref.get("title"),
+ "snippet": ref.get("snippet"),
+ }
+
+ return web_search_results
diff --git a/astrbot/dashboard/routes/chat.py b/astrbot/dashboard/routes/chat.py
index 5ff1913b9e..368348daf4 100644
--- a/astrbot/dashboard/routes/chat.py
+++ b/astrbot/dashboard/routes/chat.py
@@ -1,7 +1,6 @@
import asyncio
import json
import os
-import re
import uuid
from contextlib import asynccontextmanager
from copy import deepcopy
@@ -26,7 +25,9 @@
from astrbot.core.utils.active_event_registry import active_event_registry
from astrbot.core.utils.astrbot_path import get_astrbot_data_path
from astrbot.core.utils.datetime_utils import to_utc_isoformat
+from astrbot.core.utils.web_search_utils import build_web_search_refs
+from .message_events import build_message_saved_event
from .route import Response, Route, RouteContext
# SSE heartbeat message to keep the connection alive during long-running operations
@@ -411,66 +412,13 @@ async def _create_attachment_from_file(
def _extract_web_search_refs(
self, accumulated_text: str, accumulated_parts: list
) -> dict:
- """从消息中提取 web_search_tavily 的引用
-
- Args:
- accumulated_text: 累积的文本内容
- accumulated_parts: 累积的消息部分列表
-
- Returns:
- 包含 used 列表的字典,记录被引用的搜索结果
- """
- supported = [
- "web_search_baidu",
- "web_search_tavily",
- "web_search_bocha",
- "web_search_brave",
- ]
- # 从 accumulated_parts 中找到所有 web_search_tavily 的工具调用结果
- web_search_results = {}
- tool_call_parts = [
- p
- for p in accumulated_parts
- if p.get("type") == "tool_call" and p.get("tool_calls")
- ]
-
- for part in tool_call_parts:
- for tool_call in part["tool_calls"]:
- if tool_call.get("name") not in supported or not tool_call.get(
- "result"
- ):
- continue
- try:
- result_data = json.loads(tool_call["result"])
- for item in result_data.get("results", []):
- if idx := item.get("index"):
- web_search_results[idx] = {
- "url": item.get("url"),
- "title": item.get("title"),
- "snippet": item.get("snippet"),
- }
- except (json.JSONDecodeError, KeyError):
- pass
-
- if not web_search_results:
- return {}
-
- # 从文本中提取所有 [xxx] 标签并去重
- ref_indices = {
- m.strip() for m in re.findall(r"[(.*?)]", accumulated_text)
- }
-
- # 构建被引用的结果列表
- used_refs = []
- for ref_index in ref_indices:
- if ref_index not in web_search_results:
- continue
- payload = {"index": ref_index, **web_search_results[ref_index]}
- if favicon := sp.temporary_cache.get("_ws_favicon", {}).get(payload["url"]):
- payload["favicon"] = favicon
- used_refs.append(payload)
-
- return {"used": used_refs} if used_refs else {}
+ """从消息中提取网页搜索引用。"""
+ favicon_cache = sp.temporary_cache.get("_ws_favicon", {})
+ return build_web_search_refs(
+ accumulated_text,
+ accumulated_parts,
+ favicon_cache,
+ )
def _sanitize_message_content(self, content: dict) -> dict:
"""Normalize editable WebChat message content before persisting."""
@@ -817,7 +765,7 @@ async def flush_pending_bot_message():
message_accumulator = BotMessageAccumulator()
agent_stats = {}
refs = {}
- return saved_record
+ return saved_record, extracted_refs
def build_attachment_saved_event(part: dict | None) -> str | None:
if not part or not part.get("attachment_id") or not part.get("type"):
@@ -967,19 +915,15 @@ def build_attachment_saved_event(part: dict | None) -> str | None:
should_save = True
if should_save:
- saved_record = await flush_pending_bot_message()
+ flush_result = await flush_pending_bot_message()
# 发送保存的消息信息给前端
- if saved_record and not client_disconnected:
- saved_info = {
- "type": "message_saved",
- "data": {
- "id": saved_record.id,
- "created_at": to_utc_isoformat(
- saved_record.created_at
- ),
- "llm_checkpoint_id": llm_checkpoint_id,
- },
- }
+ if flush_result and not client_disconnected:
+ saved_record, saved_refs = flush_result
+ saved_info = build_message_saved_event(
+ saved_record,
+ saved_refs,
+ llm_checkpoint_id=llm_checkpoint_id,
+ )
try:
yield f"data: {json.dumps(saved_info, ensure_ascii=False)}\n\n"
except Exception:
diff --git a/astrbot/dashboard/routes/live_chat.py b/astrbot/dashboard/routes/live_chat.py
index d7705882db..8239eb6e30 100644
--- a/astrbot/dashboard/routes/live_chat.py
+++ b/astrbot/dashboard/routes/live_chat.py
@@ -1,7 +1,6 @@
import asyncio
import json
import os
-import re
import time
import uuid
import wave
@@ -22,12 +21,14 @@
from astrbot.core.platform.sources.webchat.webchat_queue_mgr import webchat_queue_mgr
from astrbot.core.utils.astrbot_path import get_astrbot_data_path, get_astrbot_temp_path
from astrbot.core.utils.datetime_utils import to_utc_isoformat
+from astrbot.core.utils.web_search_utils import build_web_search_refs
from .chat import (
BotMessageAccumulator,
build_bot_history_content,
collect_plain_text_from_message_parts,
)
+from .message_events import build_message_saved_event
from .route import Route, RouteContext
@@ -203,54 +204,12 @@ def _extract_web_search_refs(
self, accumulated_text: str, accumulated_parts: list
) -> dict:
"""从消息中提取 web_search 引用。"""
- supported = [
- "web_search_baidu",
- "web_search_tavily",
- "web_search_bocha",
- "web_search_brave",
- ]
- web_search_results = {}
- tool_call_parts = [
- p
- for p in accumulated_parts
- if p.get("type") == "tool_call" and p.get("tool_calls")
- ]
-
- for part in tool_call_parts:
- for tool_call in part["tool_calls"]:
- if tool_call.get("name") not in supported or not tool_call.get(
- "result"
- ):
- continue
- try:
- result_data = json.loads(tool_call["result"])
- for item in result_data.get("results", []):
- if idx := item.get("index"):
- web_search_results[idx] = {
- "url": item.get("url"),
- "title": item.get("title"),
- "snippet": item.get("snippet"),
- }
- except (json.JSONDecodeError, KeyError):
- pass
-
- if not web_search_results:
- return {}
-
- ref_indices = {
- m.strip() for m in re.findall(r"[(.*?)]", accumulated_text)
- }
-
- used_refs = []
- for ref_index in ref_indices:
- if ref_index not in web_search_results:
- continue
- payload = {"index": ref_index, **web_search_results[ref_index]}
- if favicon := sp.temporary_cache.get("_ws_favicon", {}).get(payload["url"]):
- payload["favicon"] = favicon
- used_refs.append(payload)
-
- return {"used": used_refs} if used_refs else {}
+ favicon_cache = sp.temporary_cache.get("_ws_favicon", {})
+ return build_web_search_refs(
+ accumulated_text,
+ accumulated_parts,
+ favicon_cache,
+ )
async def _save_bot_message(
self,
@@ -533,7 +492,7 @@ async def flush_pending_bot_message():
message_accumulator = BotMessageAccumulator()
agent_stats = {}
refs = {}
- return saved_record
+ return saved_record, extracted_refs
pending_bot_message_flusher = flush_pending_bot_message
@@ -633,21 +592,17 @@ async def send_attachment_saved_event(part: dict | None) -> None:
should_save = True
if should_save:
- saved_record = await flush_pending_bot_message()
- if saved_record:
+ flush_result = await flush_pending_bot_message()
+ if flush_result:
+ saved_record, saved_refs = flush_result
await self._send_chat_payload(
session,
- {
- "ct": "chat",
- "type": "message_saved",
- "data": {
- "id": saved_record.id,
- "created_at": to_utc_isoformat(
- saved_record.created_at
- ),
- "llm_checkpoint_id": llm_checkpoint_id,
- },
- },
+ build_message_saved_event(
+ saved_record,
+ saved_refs,
+ llm_checkpoint_id=llm_checkpoint_id,
+ chat_mode=True,
+ ),
)
if msg_type == "end":
diff --git a/astrbot/dashboard/routes/message_events.py b/astrbot/dashboard/routes/message_events.py
new file mode 100644
index 0000000000..7207ee7361
--- /dev/null
+++ b/astrbot/dashboard/routes/message_events.py
@@ -0,0 +1,24 @@
+from astrbot.core.utils.datetime_utils import to_utc_isoformat
+
+
+def build_message_saved_event(
+ saved_record,
+ refs: dict | None = None,
+ *,
+ llm_checkpoint_id: str | None = None,
+ chat_mode: bool = False,
+) -> dict:
+ payload = {
+ "type": "message_saved",
+ "data": {
+ "id": saved_record.id,
+ "created_at": to_utc_isoformat(saved_record.created_at),
+ },
+ }
+ if refs:
+ payload["data"]["refs"] = refs
+ if llm_checkpoint_id is not None:
+ payload["data"]["llm_checkpoint_id"] = llm_checkpoint_id
+ if chat_mode:
+ payload["ct"] = "chat"
+ return payload
diff --git a/dashboard/src/i18n/locales/en-US/features/config-metadata.json b/dashboard/src/i18n/locales/en-US/features/config-metadata.json
index 689c460d83..9aceeb3853 100644
--- a/dashboard/src/i18n/locales/en-US/features/config-metadata.json
+++ b/dashboard/src/i18n/locales/en-US/features/config-metadata.json
@@ -117,6 +117,10 @@
"description": "Tavily API Key",
"hint": "Multiple keys can be added for rotation."
},
+ "websearch_tavily_base_url": {
+ "description": "Tavily API Base URL",
+ "hint": "Default: https://api.tavily.com. Change to use a proxy or self-hosted instance."
+ },
"websearch_bocha_key": {
"description": "BoCha API Key",
"hint": "Multiple keys can be added for rotation."
@@ -133,6 +137,14 @@
"description": "Baidu Qianfan Smart Cloud APP Builder API Key",
"hint": "Reference: [https://console.bce.baidu.com/iam/#/iam/apikey/list](https://console.bce.baidu.com/iam/#/iam/apikey/list)"
},
+ "websearch_exa_key": {
+ "description": "Exa API Key",
+ "hint": "Multiple keys can be added for rotation."
+ },
+ "websearch_exa_base_url": {
+ "description": "Exa API Base URL",
+ "hint": "Default: https://api.exa.ai. Change to use a proxy or self-hosted instance."
+ },
"web_search_link": {
"description": "Display Source Citations"
}
diff --git a/dashboard/src/i18n/locales/ru-RU/features/config-metadata.json b/dashboard/src/i18n/locales/ru-RU/features/config-metadata.json
index ec124eeeec..0202426373 100644
--- a/dashboard/src/i18n/locales/ru-RU/features/config-metadata.json
+++ b/dashboard/src/i18n/locales/ru-RU/features/config-metadata.json
@@ -117,6 +117,10 @@
"description": "API-ключ Tavily",
"hint": "Можно добавить несколько ключей для ротации."
},
+ "websearch_tavily_base_url": {
+ "description": "Базовый URL API Tavily",
+ "hint": "По умолчанию: https://api.tavily.com. Можно изменить на прокси-адрес."
+ },
"websearch_bocha_key": {
"description": "API-ключ BoCha",
"hint": "Можно добавить несколько ключей для ротации."
@@ -133,6 +137,14 @@
"description": "API-ключ Baidu Qianfan APP Builder",
"hint": "Ссылка: [https://console.bce.baidu.com/iam/#/iam/apikey/list](https://console.bce.baidu.com/iam/#/iam/apikey/list)"
},
+ "websearch_exa_key": {
+ "description": "API-ключ Exa",
+ "hint": "Можно добавить несколько ключей для ротации."
+ },
+ "websearch_exa_base_url": {
+ "description": "Базовый URL API Exa",
+ "hint": "По умолчанию: https://api.exa.ai. Можно изменить на прокси-адрес."
+ },
"web_search_link": {
"description": "Показывать ссылки на источники"
}
diff --git a/dashboard/src/i18n/locales/zh-CN/features/config-metadata.json b/dashboard/src/i18n/locales/zh-CN/features/config-metadata.json
index 73f6903bbe..0d1e807099 100644
--- a/dashboard/src/i18n/locales/zh-CN/features/config-metadata.json
+++ b/dashboard/src/i18n/locales/zh-CN/features/config-metadata.json
@@ -119,6 +119,10 @@
"description": "Tavily API Key",
"hint": "可添加多个 Key 进行轮询。"
},
+ "websearch_tavily_base_url": {
+ "description": "Tavily API Base URL",
+ "hint": "默认为 https://api.tavily.com,可改为代理地址。"
+ },
"websearch_bocha_key": {
"description": "BoCha API Key",
"hint": "可添加多个 Key 进行轮询。"
@@ -135,6 +139,14 @@
"description": "百度千帆智能云 APP Builder API Key",
"hint": "参考:[https://console.bce.baidu.com/iam/#/iam/apikey/list](https://console.bce.baidu.com/iam/#/iam/apikey/list)"
},
+ "websearch_exa_key": {
+ "description": "Exa API Key",
+ "hint": "可添加多个 Key 进行轮询。"
+ },
+ "websearch_exa_base_url": {
+ "description": "Exa API Base URL",
+ "hint": "默认为 https://api.exa.ai,可改为代理地址。"
+ },
"web_search_link": {
"description": "显示来源引用"
}
diff --git a/docs/en/use/websearch.md b/docs/en/use/websearch.md
index 119166d387..ff47e03429 100644
--- a/docs/en/use/websearch.md
+++ b/docs/en/use/websearch.md
@@ -14,11 +14,11 @@ When using a large language model that supports function calling with the web se
And other prompts with search intent to trigger the model to invoke the search tool.
-AstrBot currently supports 4 web search providers: `Tavily`, `BoCha`, `Baidu AI Search`, and `Brave`.
+AstrBot currently supports 5 web search providers: `Tavily`, `BoCha`, `Baidu AI Search`, `Brave`, and `Exa`.
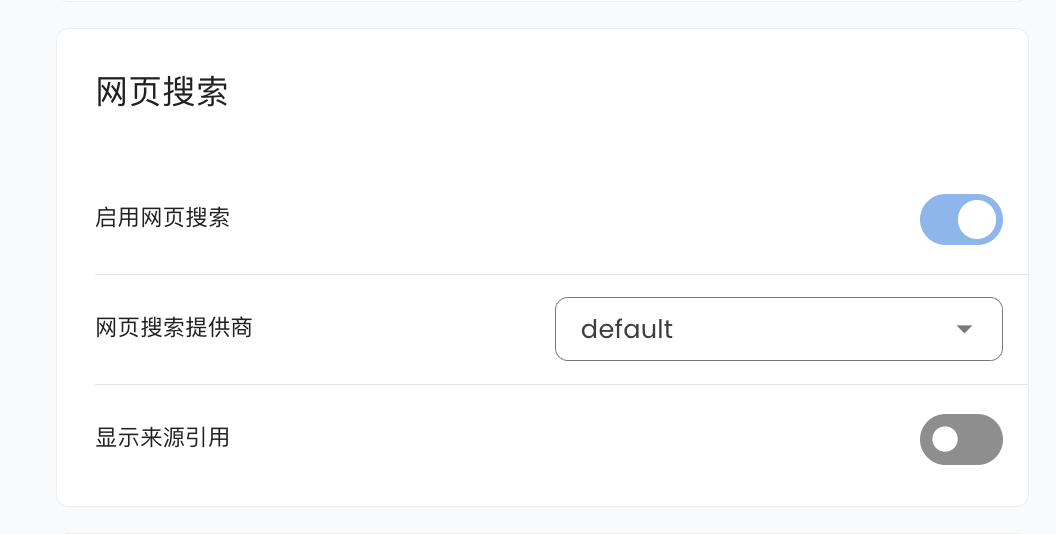
-Go to `Configuration`, scroll down to find Web Search, where you can select `Tavily`, `BoCha`, `Baidu AI Search`, or `Brave`.
+Go to `Configuration`, scroll down to find Web Search, where you can select `Tavily`, `BoCha`, `Baidu AI Search`, `Brave`, or `Exa`.
### Tavily
@@ -36,6 +36,10 @@ Get an API Key from Baidu Qianfan APP Builder, then fill it in the corresponding
Get an API Key from Brave Search, then fill it in the corresponding configuration item.
+### Exa
+
+Go to [Exa](https://dashboard.exa.ai) to get an API Key, then fill it in the corresponding configuration item.
+
If you use Tavily as your web search source, you will get a better experience optimization on AstrBot ChatUI, including citation source display and more:

diff --git a/docs/public/install.sh b/docs/public/install.sh
index 16caa08e83..9118067218 100755
--- a/docs/public/install.sh
+++ b/docs/public/install.sh
@@ -60,7 +60,7 @@ if ! has "$UV_BIN"; then
err "uv was not found after installation."
err "Please install uv manually: https://docs.astral.sh/uv/getting-started/installation/"
exit 1
-fi
+fi
ok "$("$UV_BIN" --version)"
info "Installing AstrBot with Python 3.12..."
diff --git a/docs/zh/use/websearch.md b/docs/zh/use/websearch.md
index 9173d40ad7..bdfdc99bc0 100644
--- a/docs/zh/use/websearch.md
+++ b/docs/zh/use/websearch.md
@@ -4,24 +4,24 @@
AstrBot 内置的网页搜索功能依赖大模型提供 `函数调用` 能力。如果你不了解函数调用,请参考:[函数调用](/use/websearch)。
-在使用支持函数调用的大模型且开启了网页搜索功能的情况下,您可以试着说:
+在使用支持函数调用的大模型且开启了网页搜索功能的情况下,你可以试着说:
- `帮我搜索一下 xxx`
- `帮我总结一下这个链接:https://soulter.top`
- `查一下 xxx`
- `最近 xxxx`
-等等带有搜索意味的提示让大模型触发调用搜索工具。
+等等带有搜索意味的提示,让大模型触发调用搜索工具。
-AstrBot 当前支持 4 种网页搜索源接入方式:`Tavily`、`BoCha`、`百度 AI 搜索`、`Brave`。
+AstrBot 当前支持 5 种网页搜索源接入方式:`Tavily`、`BoCha`、`百度 AI 搜索`、`Brave`、`Exa`。

-进入 `配置`,下拉找到网页搜索,您可选择 `Tavily`、`BoCha`、`百度 AI 搜索` 或 `Brave`。
+进入 `配置`,下拉找到网页搜索,你可选择 `Tavily`、`BoCha`、`百度 AI 搜索`、`Brave` 或 `Exa`。
### Tavily
-前往 [Tavily](https://app.tavily.com/home) 得到 API Key,然后填写在相应的配置项。
+前往 [Tavily](https://app.tavily.com/home) 获取 API Key,然后填写在相应的配置项。
### BoCha
@@ -35,6 +35,10 @@ AstrBot 当前支持 4 种网页搜索源接入方式:`Tavily`、`BoCha`、`
前往 Brave Search 获取 API Key,然后填写在相应的配置项。
-如果您使用 Tavily 作为网页搜索源,在 AstrBot ChatUI 上将会获得更好的体验优化,包括引用来源展示等:
+### Exa
+
+前往 [Exa](https://dashboard.exa.ai) 获取 API Key,然后填写在相应的配置项。
+
+如果你使用 Tavily 作为网页搜索源,在 AstrBot ChatUI 上会获得更好的体验优化,包括引用来源展示等:

diff --git a/tests/test_chat_route.py b/tests/test_chat_route.py
index 47bd747a04..2855fa179d 100644
--- a/tests/test_chat_route.py
+++ b/tests/test_chat_route.py
@@ -1,8 +1,12 @@
import asyncio
+from datetime import datetime, timezone
+from types import SimpleNamespace
import pytest
+from astrbot.core.utils.datetime_utils import to_utc_isoformat
from astrbot.dashboard.routes.chat import _poll_webchat_stream_result
+from astrbot.dashboard.routes.message_events import build_message_saved_event
class _QueueThatRaises:
@@ -54,3 +58,62 @@ async def test_poll_webchat_stream_result_returns_queue_payload():
assert result == payload
assert should_break is False
+
+
+@pytest.mark.parametrize("chat_mode", [False, True])
+def test_build_message_saved_event_includes_refs(chat_mode: bool):
+ saved_record = SimpleNamespace(
+ id=42,
+ created_at=datetime(2026, 4, 21, 12, 0, tzinfo=timezone.utc),
+ )
+ refs = {
+ "used": [
+ {
+ "index": "abcd.1",
+ "url": "https://example.com",
+ "title": "Example",
+ }
+ ]
+ }
+
+ payload = build_message_saved_event(saved_record, refs, chat_mode=chat_mode)
+
+ expected = {
+ "type": "message_saved",
+ "data": {
+ "id": 42,
+ "created_at": to_utc_isoformat(saved_record.created_at),
+ "refs": refs,
+ },
+ }
+ if chat_mode:
+ expected["ct"] = "chat"
+
+ assert payload == expected
+
+
+@pytest.mark.parametrize("chat_mode", [False, True])
+def test_build_message_saved_event_includes_checkpoint_id(chat_mode: bool):
+ saved_record = SimpleNamespace(
+ id=42,
+ created_at=datetime(2026, 4, 21, 12, 0, tzinfo=timezone.utc),
+ )
+
+ payload = build_message_saved_event(
+ saved_record,
+ llm_checkpoint_id="checkpoint-1",
+ chat_mode=chat_mode,
+ )
+
+ expected = {
+ "type": "message_saved",
+ "data": {
+ "id": 42,
+ "created_at": to_utc_isoformat(saved_record.created_at),
+ "llm_checkpoint_id": "checkpoint-1",
+ },
+ }
+ if chat_mode:
+ expected["ct"] = "chat"
+
+ assert payload == expected
diff --git a/tests/unit/test_upload_filename_sanitization.py b/tests/unit/test_upload_filename_sanitization.py
index 88374669ec..0bf817d0b4 100644
--- a/tests/unit/test_upload_filename_sanitization.py
+++ b/tests/unit/test_upload_filename_sanitization.py
@@ -29,4 +29,3 @@ def test_sanitize_upload_filename_removes_embedded_null_bytes():
assert _sanitize_upload_filename("\x00leading.txt") == "leading.txt"
assert _sanitize_upload_filename("trailing\x00.txt\x00") == "trailing.txt"
assert _sanitize_upload_filename("mid\x00dle.txt") == "middle.txt"
-
diff --git a/tests/unit/test_web_search_tools.py b/tests/unit/test_web_search_tools.py
index c0ac3cf800..507ba635ba 100644
--- a/tests/unit/test_web_search_tools.py
+++ b/tests/unit/test_web_search_tools.py
@@ -3,6 +3,8 @@
import pytest
+import astrbot.core.tools.registry as tool_registry
+from astrbot.core.knowledge_base.parsers.url_parser import URLExtractor
from astrbot.core.tools import web_search_tools as tools
@@ -15,17 +17,338 @@ def save_config(self):
self.saved = True
-def test_normalize_legacy_web_search_config_migrates_firecrawl_key():
+class _FakeExaResponse:
+ def __init__(self, payload: dict):
+ self.status = 200
+ self._payload = payload
+
+ async def __aenter__(self):
+ return self
+
+ async def __aexit__(self, exc_type, exc, tb):
+ return False
+
+ async def json(self):
+ return self._payload
+
+ async def text(self):
+ return ""
+
+
+class _FakeExaSession:
+ def __init__(self, payload: dict, captured: dict[str, object]):
+ self._payload = payload
+ self._captured = captured
+
+ async def __aenter__(self):
+ return self
+
+ async def __aexit__(self, exc_type, exc, tb):
+ return False
+
+ def post(self, url: str, **kwargs):
+ self._captured["url"] = url
+ self._captured["kwargs"] = kwargs
+ return _FakeExaResponse(self._payload)
+
+
+class _FakeFirecrawlResponse:
+ def __init__(self, status=200, json_data=None, text_data=""):
+ self.status = status
+ self.json_data = json_data or {}
+ self.text_data = text_data
+
+ async def __aenter__(self):
+ return self
+
+ async def __aexit__(self, exc_type, exc, tb):
+ return None
+
+ async def json(self):
+ return self.json_data
+
+ async def text(self):
+ return self.text_data
+
+
+class _FakeFirecrawlSession:
+ def __init__(self, response):
+ self.response = response
+ self.trust_env = None
+ self.entered = False
+ self.exited = False
+ self.posted = None
+
+ async def __aenter__(self):
+ self.entered = True
+ return self
+
+ async def __aexit__(self, exc_type, exc, tb):
+ self.exited = True
+ return None
+
+ def post(self, url, json, headers):
+ self.posted = {"url": url, "json": json, "headers": headers}
+ return self.response
+
+
+def _context_with_provider_settings(provider_settings):
+ config = {"provider_settings": provider_settings}
+ agent_context = SimpleNamespace(
+ context=SimpleNamespace(get_config=lambda umo: config),
+ event=SimpleNamespace(unified_msg_origin="test:private:session"),
+ )
+ return SimpleNamespace(context=agent_context)
+
+
+def test_normalize_legacy_web_search_config_migrates_firecrawl_and_exa_keys():
config = _FakeConfig(
- {"provider_settings": {"websearch_firecrawl_key": "firecrawl-key"}}
+ {
+ "provider_settings": {
+ "websearch_firecrawl_key": "firecrawl-key",
+ "websearch_exa_key": "exa-key",
+ }
+ }
)
tools.normalize_legacy_web_search_config(config)
assert config["provider_settings"]["websearch_firecrawl_key"] == ["firecrawl-key"]
+ assert config["provider_settings"]["websearch_exa_key"] == ["exa-key"]
assert config.saved is True
+@pytest.mark.asyncio
+@pytest.mark.parametrize(
+ ("search_type", "expected"),
+ [
+ ("auto", "auto"),
+ ("neural", "neural"),
+ ("fast", "fast"),
+ ("deep-lite", "deep-lite"),
+ ("deep", "deep"),
+ ("deep-reasoning", "deep-reasoning"),
+ ("instant", "instant"),
+ (" INSTANT ", "instant"),
+ ("unsupported", "auto"),
+ ],
+)
+async def test_exa_web_search_tool_normalizes_search_type(
+ monkeypatch: pytest.MonkeyPatch,
+ search_type: str,
+ expected: str,
+):
+ captured: dict[str, object] = {}
+
+ async def fake_exa_search(provider_settings: dict, payload: dict, timeout: int):
+ captured["provider_settings"] = provider_settings
+ captured["payload"] = payload
+ captured["timeout"] = timeout
+ return []
+
+ monkeypatch.setattr(tools, "_exa_search", fake_exa_search)
+
+ tool = tools.ExaWebSearchTool()
+ result = await tool.call(
+ _context_with_provider_settings({"websearch_exa_key": ["test-key"]}),
+ query="AstrBot",
+ search_type=search_type,
+ )
+
+ assert result == "Error: Exa web searcher does not return any results."
+ assert captured["payload"]["type"] == expected
+
+
+@pytest.mark.asyncio
+async def test_exa_web_search_tool_uses_default_for_invalid_max_results(
+ monkeypatch: pytest.MonkeyPatch,
+):
+ captured: dict[str, object] = {}
+
+ async def fake_exa_search(provider_settings: dict, payload: dict, timeout: int):
+ captured["payload"] = payload
+ return []
+
+ monkeypatch.setattr(tools, "_exa_search", fake_exa_search)
+
+ tool = tools.ExaWebSearchTool()
+ result = await tool.call(
+ _context_with_provider_settings({"websearch_exa_key": ["test-key"]}),
+ query="AstrBot",
+ max_results="not-a-number",
+ )
+
+ assert result == "Error: Exa web searcher does not return any results."
+ assert captured["payload"]["numResults"] == 10
+
+
+@pytest.mark.asyncio
+async def test_exa_find_similar_uses_default_for_invalid_max_results(
+ monkeypatch: pytest.MonkeyPatch,
+):
+ captured: dict[str, object] = {}
+
+ async def fake_exa_find_similar(
+ provider_settings: dict,
+ payload: dict,
+ timeout: int,
+ ):
+ captured["payload"] = payload
+ return []
+
+ monkeypatch.setattr(tools, "_exa_find_similar", fake_exa_find_similar)
+
+ tool = tools.ExaFindSimilarTool()
+ result = await tool.call(
+ _context_with_provider_settings({"websearch_exa_key": ["test-key"]}),
+ url="https://example.com",
+ max_results="not-a-number",
+ )
+
+ assert result == "Error: Exa find similar does not return any results."
+ assert captured["payload"]["numResults"] == 10
+
+
+def test_get_exa_base_url_rejects_endpoint_path():
+ with pytest.raises(ValueError) as exc_info:
+ tools._get_exa_base_url({"websearch_exa_base_url": "https://api.exa.ai/search"})
+
+ assert str(exc_info.value) == (
+ "Error: Exa API Base URL must be a base URL or proxy prefix, "
+ "not a specific endpoint path. Received: 'https://api.exa.ai/search'."
+ )
+
+
+def test_url_extractor_rejects_endpoint_base_url():
+ with pytest.raises(ValueError) as exc_info:
+ URLExtractor(
+ ["test-key"],
+ tavily_base_url="https://api.tavily.com/extract",
+ )
+
+ assert str(exc_info.value) == (
+ "Error: Tavily API Base URL must be a base URL or proxy prefix, "
+ "not a specific endpoint path. Received: 'https://api.tavily.com/extract'."
+ )
+
+
+def test_bocha_builtin_config_statuses_are_registered():
+ rule = tool_registry._BUILTIN_TOOL_CONFIG_RULES.get("web_search_bocha")
+
+ assert rule is not None
+ statuses = rule.evaluate(
+ {
+ "provider_settings": {
+ "web_search": True,
+ "websearch_provider": "bocha",
+ }
+ }
+ )
+
+ assert statuses == [
+ {
+ "key": "provider_settings.web_search",
+ "operator": "equals",
+ "expected": True,
+ "actual": True,
+ "matched": True,
+ "message": None,
+ },
+ {
+ "key": "provider_settings.websearch_provider",
+ "operator": "equals",
+ "expected": "bocha",
+ "actual": "bocha",
+ "matched": True,
+ "message": None,
+ },
+ ]
+
+
+@pytest.mark.asyncio
+@pytest.mark.parametrize(
+ ("helper_name", "payload"),
+ [
+ ("_exa_search", {"query": "AstrBot"}),
+ ("_exa_find_similar", {"url": "https://example.com"}),
+ ],
+)
+async def test_exa_helpers_preserve_favicon(
+ monkeypatch: pytest.MonkeyPatch,
+ helper_name: str,
+ payload: dict,
+):
+ captured: dict[str, object] = {}
+ response_payload = {
+ "results": [
+ {
+ "title": "Example",
+ "url": "https://example.com",
+ "text": "Snippet",
+ "favicon": "https://example.com/favicon.ico",
+ }
+ ]
+ }
+
+ async def fake_get(provider_settings: dict) -> str:
+ return "test-key"
+
+ monkeypatch.setattr(tools._EXA_KEY_ROTATOR, "get", fake_get)
+ monkeypatch.setattr(
+ tools.aiohttp,
+ "ClientSession",
+ lambda **kwargs: _FakeExaSession(response_payload, captured),
+ )
+
+ helper = getattr(tools, helper_name)
+ results = await helper(
+ {"websearch_exa_key": ["test-key"]},
+ payload,
+ )
+
+ assert captured["url"]
+ assert results[0].favicon == "https://example.com/favicon.ico"
+
+
+@pytest.mark.asyncio
+async def test_exa_extract_raises_status_error(monkeypatch: pytest.MonkeyPatch):
+ response_payload = {
+ "results": [],
+ "statuses": [
+ {
+ "id": "https://example.com/missing",
+ "status": "error",
+ "error": {
+ "tag": "CRAWL_NOT_FOUND",
+ "httpStatusCode": 404,
+ },
+ }
+ ],
+ }
+ captured: dict[str, object] = {}
+
+ async def fake_get(provider_settings: dict) -> str:
+ return "test-key"
+
+ monkeypatch.setattr(tools._EXA_KEY_ROTATOR, "get", fake_get)
+ monkeypatch.setattr(
+ tools.aiohttp,
+ "ClientSession",
+ lambda **kwargs: _FakeExaSession(response_payload, captured),
+ )
+
+ with pytest.raises(ValueError) as exc_info:
+ await tools._exa_extract(
+ {"websearch_exa_key": ["test-key"]},
+ {"urls": ["https://example.com/missing"], "text": True},
+ )
+
+ assert str(exc_info.value) == (
+ "Error: Exa content extraction failed: "
+ "https://example.com/missing: CRAWL_NOT_FOUND (HTTP 404)"
+ )
+
+
@pytest.mark.asyncio
async def test_firecrawl_search_maps_web_results(monkeypatch):
async def fake_firecrawl_search(provider_settings, payload):
@@ -51,13 +374,14 @@ async def fake_firecrawl_search(provider_settings, payload):
)
result = await tool.call(context, query="AstrBot", limit=3, country="US")
+ parsed = json.loads(result)
- assert json.loads(result)["results"] == [
+ assert parsed["results"] == [
{
"title": "AstrBot",
"url": "https://example.com",
"snippet": "Search result",
- "index": json.loads(result)["results"][0]["index"],
+ "index": parsed["results"][0]["index"],
}
]
@@ -329,52 +653,3 @@ def fake_client_session(*, trust_env):
assert session.trust_env is True
assert session.entered is True
assert session.exited is True
-
-
-class _FakeFirecrawlResponse:
- def __init__(self, status=200, json_data=None, text_data=""):
- self.status = status
- self.json_data = json_data or {}
- self.text_data = text_data
-
- async def __aenter__(self):
- return self
-
- async def __aexit__(self, exc_type, exc, tb):
- return None
-
- async def json(self):
- return self.json_data
-
- async def text(self):
- return self.text_data
-
-
-class _FakeFirecrawlSession:
- def __init__(self, response):
- self.response = response
- self.trust_env = None
- self.entered = False
- self.exited = False
- self.posted = None
-
- async def __aenter__(self):
- self.entered = True
- return self
-
- async def __aexit__(self, exc_type, exc, tb):
- self.exited = True
- return None
-
- def post(self, url, json, headers):
- self.posted = {"url": url, "json": json, "headers": headers}
- return self.response
-
-
-def _context_with_provider_settings(provider_settings):
- config = {"provider_settings": provider_settings}
- agent_context = SimpleNamespace(
- context=SimpleNamespace(get_config=lambda umo: config),
- event=SimpleNamespace(unified_msg_origin="test:private:session"),
- )
- return SimpleNamespace(context=agent_context)
diff --git a/tests/unit/test_web_search_utils.py b/tests/unit/test_web_search_utils.py
new file mode 100644
index 0000000000..2f619eb66e
--- /dev/null
+++ b/tests/unit/test_web_search_utils.py
@@ -0,0 +1,172 @@
+import json
+
+import pytest
+
+from astrbot.core.utils.web_search_utils import (
+ build_web_search_refs,
+ collect_web_search_ref_items,
+ collect_web_search_results,
+ normalize_web_search_base_url,
+)
+
+
+def _make_web_search_parts() -> list[dict]:
+ return [
+ {
+ "type": "tool_call",
+ "tool_calls": [
+ {
+ "name": "web_search_exa",
+ "result": json.dumps(
+ {
+ "results": [
+ {
+ "index": "a152.1",
+ "url": "https://example.com/1",
+ "title": "Example 1",
+ "snippet": "Snippet 1",
+ },
+ {
+ "index": "a152.2",
+ "url": "https://example.com/2",
+ "title": "Example 2",
+ "snippet": "Snippet 2",
+ },
+ ]
+ }
+ ),
+ }
+ ],
+ }
+ ]
+
+
+def test_collect_web_search_results_builds_index_mapping():
+ results = collect_web_search_results(_make_web_search_parts())
+
+ assert results == {
+ "a152.1": {
+ "url": "https://example.com/1",
+ "title": "Example 1",
+ "snippet": "Snippet 1",
+ },
+ "a152.2": {
+ "url": "https://example.com/2",
+ "title": "Example 2",
+ "snippet": "Snippet 2",
+ },
+ }
+
+
+def test_collect_web_search_ref_items_preserves_order_and_favicon():
+ refs = collect_web_search_ref_items(
+ _make_web_search_parts(),
+ {"https://example.com/2": "https://example.com/favicon.ico"},
+ )
+
+ assert [ref["index"] for ref in refs] == ["a152.1", "a152.2"]
+ assert "favicon" not in refs[0]
+ assert refs[1]["favicon"] == "https://example.com/favicon.ico"
+
+
+def test_build_web_search_refs_uses_explicit_ref_indices_in_text_order():
+ refs = build_web_search_refs(
+ "Second [a152.2] first [a152.1]",
+ _make_web_search_parts(),
+ )
+
+ assert [ref["index"] for ref in refs["used"]] == ["a152.2", "a152.1"]
+
+
+def test_build_web_search_refs_falls_back_to_all_results_without_refs():
+ refs = build_web_search_refs("No explicit refs here.", _make_web_search_parts())
+
+ assert [ref["index"] for ref in refs["used"]] == ["a152.1", "a152.2"]
+
+
+def test_build_web_search_refs_ignores_tool_call_id_and_falls_back():
+ refs = build_web_search_refs(
+ "[call_a73499ddbaf845dba8310e44]",
+ _make_web_search_parts(),
+ )
+
+ assert [ref["index"] for ref in refs["used"]] == ["a152.1", "a152.2"]
+
+
+@pytest.mark.parametrize(
+ ("base_url", "expected_message"),
+ [
+ (
+ "exa.ai/search",
+ "Error: Exa API Base URL must start with http:// or https://. "
+ "Proxy base paths are allowed. Received: 'exa.ai/search'.",
+ ),
+ ],
+)
+def test_normalize_web_search_base_url_reports_invalid_value(
+ base_url: str, expected_message: str
+):
+ with pytest.raises(ValueError) as exc_info:
+ normalize_web_search_base_url(
+ base_url,
+ default="https://api.exa.ai",
+ provider_name="Exa",
+ )
+
+ assert str(exc_info.value) == expected_message
+
+
+@pytest.mark.parametrize(
+ ("base_url", "expected"),
+ [
+ (" https://api.exa.ai/ ", "https://api.exa.ai"),
+ ("https://proxy.example.com/exa/", "https://proxy.example.com/exa"),
+ ],
+)
+def test_normalize_web_search_base_url_accepts_proxy_paths(
+ base_url: str, expected: str
+):
+ normalized = normalize_web_search_base_url(
+ base_url,
+ default="https://api.exa.ai",
+ provider_name="Exa",
+ )
+
+ assert normalized == expected
+
+
+@pytest.mark.parametrize(
+ ("base_url", "provider_name", "disallowed_path_suffixes", "expected_message"),
+ [
+ (
+ "https://api.exa.ai/search",
+ "Exa",
+ ("search", "contents", "findSimilar"),
+ "Error: Exa API Base URL must be a base URL or proxy prefix, "
+ "not a specific endpoint path. Received: 'https://api.exa.ai/search'.",
+ ),
+ (
+ "https://api.tavily.com/extract",
+ "Tavily",
+ ("search", "extract"),
+ "Error: Tavily API Base URL must be a base URL or proxy prefix, "
+ "not a specific endpoint path. Received: "
+ "'https://api.tavily.com/extract'.",
+ ),
+ ],
+)
+def test_normalize_web_search_base_url_rejects_endpoint_paths(
+ base_url: str,
+ provider_name: str,
+ disallowed_path_suffixes: tuple[str, ...],
+ expected_message: str,
+):
+ with pytest.raises(ValueError) as exc_info:
+ normalize_web_search_base_url(
+ base_url,
+ default="https://api.exa.ai",
+ provider_name=provider_name,
+ disallowed_path_suffixes=disallowed_path_suffixes,
+ )
+
+ assert str(exc_info.value) == expected_message